[I have updated the post below, with some considerations from the past similar initiative by Sun (now Oracle) of the Open Media Commons, that designed a codec based on enhancement of H261+]
There is a substantial interest on the recently released WebM codec and specification from Google, the result of open sourcing the VP8 SDK from the recently acquired company On2. It clearly sparked the interest of many the idea of having a reasonably good, open and freely redistributable codec for which the patents are freely licensed in a way that is compatible with open source and free software licensing; at the same time, the results of initial analysis by Dark Shikari (real name Jason Garrett-Glaser, the author of the extraordinary x264 encoder) and others seem to indicate that the patent problem is actually not solved at all.
I believe that some of the comments (especially in Dark Shikari’s post) are a little bit off mark, and should be taken in the correct context; for this reason, I will first of all provide a little background.
What is WebM? WebM is the result of the open sourcing of the VP8 encoding system, previously owned by On2 technologies. It is composed of three parts: the bitstream specification, the reference encoder (that takes an uncompressed video sequence and creates a compressed bitstream) and the reference decoder (that takes the compressed bitstream and generates a decoded video stream). I stress the word “reference” because this is only one of the possible implementations; exactly like the H264 standard, there are many encoders and decoders, optimized for different things (or of different quality). An example of a “perfect” encoder may be a program that generates all possible bit sequences, decodes them (discarding the non-conforming ones), compares with the uncompressed original video and retains the one with the highest quality (measured using PSNR or some other metric). It would make for a very slow encoder, but would find the perfect sequence; that is, the smallest one that has the highest PSNR; on the other hand, decoders differ in precision, speed and memory consumption, making it difficult to decide which is the “best”.
Before delving into the specific of the post, let’s mention two other little things: to the contrary of what is widely reported, Microsoft VC1 never was “patent free”. It was free for use with Windows, because Microsoft was assumed to have all the patents necessary for its implementation; but as VC1 was basically an MPEG4 derivative, most of the patents there applies to VC1 as well, plus some other that were found later for the enhanced filtering that is part of the specification (and that were also part of the MPEG4 Advanced profile and H264). It was never “patent free”, it was licensed without a fee. (that is a substantially different thing – and one of the reasons for its disappearance. MS pays the MPEG-LA for every use of it, and receives nothing back, making it a money-loss proposition…)
Another important aspect is the prior patent search: it is clear (and will be evident a few lines down) that On2 made a patent search to avoid specific implementation details; the point is that noone will be able to see this pre-screening,to avoid additional damages. In fact, one of the most brain damaged things of the current software patent situation is the fact that if a company performs a patent search and finds a potential infringing patent it may incur in additional damages for willful infringement (called “treble damages”). So, the actual approach is to perform the same analysis, try to work around any potential infringing patent, and for those “close enough” cases that cannot be avoided try to steer away as much as possible. So, calling Google out for releasing the study on possible patent infringement is something that has no sense at all: they will never release it to the public.
So, go on with the analysis.
Dark Shikari makes several considerations, some related to the implementation itself, and many related to its “patent status”. For example: “VP8ŌĆÖs intra prediction is basically ripped off wholesale from H.264″, without mentioning that the intra prediction mode is actually pre-dating H264; actually, it was part of Nokia MVC proposal and H263++ extensions published in 2000, and the specific WebM implementation is different from the one mentioned in the “essential patents” of H264 as specified by the MPEG-LA.
If you go through the post, you will find lots of curious mentions of “sub-optimal” choices:
- “i8├Ś8, from H.264 High Profile, is not present”
- “planar prediction mode has been replaced with TM_PRED”
- “VP8 supports a total of 3 reference frames: the previous frame, the ŌĆ£alt refŌĆØ frame, and the golden frame”
- “VP8 reference frames: up to 3; H.264 reference frames: up to 16″
- “VP8 partition types: 16├Ś16, 16├Ś8, 8├Ś16, 8├Ś8, 4├Ś4; H.264 partition types: 16├Ś16, 16├Ś8, 8├Ś16, flexible subpartitions (each 8├Ś8 can be 8├Ś8, 8├Ś4, 4├Ś8, or 4├Ś4)”
- “VP8 chroma MV derivation: each 4├Ś4 chroma block uses the average of colocated luma MVs; H.264 chroma MV derivation: chroma uses luma MVs directly”
- “VP8 interpolation filter: qpel, 6-tap luma, mixed 4/6-tap chroma; H.264 interpolation filter: qpel, 6-tap luma (staged filter), bilinear chroma”
- “H.264 has but VP8 doesnŌĆÖt: B-frames, weighted prediction”
- “H.264 has a significantly better and more flexible referencing structure”
- “having as high as 6 taps on chroma [for VP8] is, IMO, completely unnecessary and wasteful [personal note: because smaller taps are all patented
 ]“
]“ - “the 8├Ś8 transform is omitted entirely”
- “H.264 uses an extremely simplified ŌĆ£DCTŌĆØ which is so un-DCT-like that it often referred to as the HCT (H.264 Cosine Transform) instead. This simplified transform results in roughly 1% worse compression, but greatly simplifies the transform itself, which can be implemented entirely with adds, subtracts, and right shifts by 1. VC-1 uses a more accurate version that relies on a few small multiplies (numbers like 17, 22, 10, etc). VP8 uses an extremely, needlessly accurate version that uses very large multiplies (20091 and 35468)”
- “The third difference is that the Hadamard hierarchical transform is applied for some inter blocks, not merely i16├Ś16″
- “unlike H.264, the hierarchical transform is luma-only and not applied to chroma “
- “For quantization, the core process is basically the same among all MPEG-like video formats, and VP8 is no exception (personal note: quantization methods are mostrly from MPEG1&2, where most patents are already expired – see the list of expired ones in MPEG-LA list)”
- “[VP8 uses] … a scheme much less flexible than H.264ŌĆÖs custom quantization matrices, it allows for adjusting the quantizer of luma DC, luma AC, chroma DC, and so forth, separately”
- “The killer mistake that VP8 has made here is not making macroblock-level quantization a core feature of VP8. Algorithms that take advantage of macroblock-level quantization are known as ŌĆ£adaptive quantizationŌĆØ and are absolutely critical to competitive visual quality” (personal note: it is basically impossible to implement adaptive quantization without infringing, especially for patents issued after 2000)
- “even the relatively suboptimal MPEG-style delta quantizer system would be a better option.┬Ā Furthermore, only 4 segment maps are allowed, for a maximum of 4 quantizers per frame (both are patented: delta quantization is part of MPEG4, and unlimited segment maps are covered)”
- “VP8 uses an arithmetic coder somewhat similar to H.264ŌĆÖs, but with a few critical differences. First, it omits the range/probability table in favor of a multiplication. Second, it is entirely non-adaptive: unlike H.264ŌĆÖs, which adapts after every bit decoded, probability values are constant over the course of the frame” (probability tables are patented in all video coding implementations, not only MPEG-specific ones, as adapting probability tables)
- “VP8 is a bit odd… it chooses an arithmetic coding context based on the neighboring MVs, then decides which of the predicted motion vectors to use, or whether to code a delta instead” (because straight delta coding is part of MPEG4)
- “The compression of the resulting delta is similar to H.264, except for the coding of very large deltas, which is slightly better (similar to FFV1ŌĆÖs Golomb-like arithmetic codes”
- “Intra prediction mode coding is done using arithmetic coding contexts based on the modes of the neighboring blocks. This is probably a good bit better than the hackneyed method that H.264 uses, which always struck me as being poorly designed”
- residual coding is different from both CABAC and CAVLC
- “VP8ŌĆÖs loop filter is vaguely similar to H.264ŌĆÖs, but with a few differences. First, it has two modes (which can be chosen by the encoder): a fast mode and a normal mode. The fast mode is somewhat simpler than H.264ŌĆÖs, while the normal mode is somewhat more complex. Secondly, when filtering between macroblocks, VP8ŌĆÖs filter has wider range than the in-macroblock filter ŌĆö H.264 did this, but only for intra edges”
- “VP8ŌĆÖs filter omits most of the adaptive strength mechanics inherent in H.264ŌĆÖs filter. Its only adaptation is that it skips filtering on p16├Ś16 blocks with no coefficients”
What we can obtain from this (very thorough – thanks, Jason!) analysis is the fact that from my point of view it is clear that On2 was actually aware of patents, and tried very hard to avoid them. It is also clear that this is in no way an assurance that there are no situation of patent infringements, only that it seems that due diligence was performed. Also, WebM is not comparable to H264 in terms of technical sophistication (it is more in line with MPEG4/VC1) but this is clearly done to avoid recent patents; some of the patents on older specification are already expired (for example, all France Telecom patents on H264 are expired), and in this sense Dark Shiraki claims that the specification is not as good as H264 is perfectly correct. It is also true that x264 beats the hell on current VP8 encoders (and basically every other encoder in the market); despite this, in a previous assessment Dark Shiraki performed a comparison of anime (cartoon) encoding and found that VP7 was better than Apple’s own H264 encode – not really that bad.
{kind=link}
The point is that reference encoders are designed to be a building block, and improvement (in respect of possible patents in the area) are certainly possible; maybe not reaching the level of x264 top quality (I suspect the psychovisual adaptive schema that allowed such a big gain in x264 are patented and non-reproducible) but it should be a worthy competitor. All in all, I suspect that MPEGLA rattling will remain only noise for a long, long time.
Update: many people mentioned in blog posts and comments that Sun Microsystem (now Oracle) in the past tried a very similar effort, namely to re-start development of a video codec based on past and expired patents, and start from there avoiding active patents to improve its competitiveness. They used the Open Media Commons IPR methodology to avoid patents and to assess patent troubles, and in particular they developed an handy chart that provides a timeline of patents and their actual status (image based on original chart obtained here):
{kind=link}
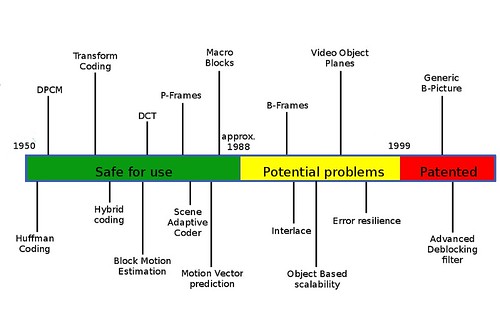
As it can be observed, most of the techniques encountered in the OMV analysis are still valid for VP8 (the advanced deblocking filter of course is present in VP8, but with a different implementation). It also provides additional support to the idea that On2 developers were aware of patents in the area, and came out with novel ideas to work around existing patents, much like Sun with its OMV initiative. In the same post, the OMV block structure graph includes several “Sun IPR” parts, that are included in the OMV specification (the latest version available here (pdf) – the site is not updated anymore) and that maybe may be re-used, with Oracle explicit permission, in WebM. And to answer people asking for “indemnification” from Google, I would like to point my readers to a presentation of OMV and in particular to slide 10: “While we are encouraged by our findings so far, the investigation continues and Sun and OMC cannot make any representations regarding encumbrances or the validity or invalidity of any patent claims or other intellectual property rights claims a third party may assert in connection with any OMC project or work product.” This should put to rest the idea that Sun was indemnifying people using OMV, exactly like I am not expecting such indemnification from Google (or any other industry player, by the way).
#1 by Fruit - May 25th, 2010 at 12:43
“in a previous assessment Dark Shiraki performed a comparison of anime (cartoon) encoding and found that VP7 was better than AppleŌĆÖs own H264 encode ŌĆō not really that bad”
You seem to be missing the main point of that, and that is that Apple’s h.264 encoder is very very bad, it is easily beaten by previous generations of technology, and that is on content for which its own format is a big advantage! In other words, it’s embearrassingly ineffective, think 2-3x more bitrate needed and you still have no certainty that there won’t be pathological problems now and there.
#2 by cdaffara - May 25th, 2010 at 17:00
Actually, I understand perfectly the issue at hand: my point was that the specification and the encoder quality are unrelated, and a good quality encoder
can overcome the inherent disadvantage of a less sophisticated specification. By the way, VP7 was also on a par with Ateme, which is considered a reasonably
good encoder…
#3 by Relgorka Shantilla - May 25th, 2010 at 18:07
Just grab some videos from YouTube. VP8 files coded by Google are about as large as Google had claimed Theora files would be. This will be trouble for all the netbooks and mobile devices that prefer LQ formats.
#4 by tunnelled Multicast AVC - May 25th, 2010 at 19:17
“VC1 was basically an MPEG4 derivative, most of the patents there applies to VC1 as well, plus some other that were found later for the enhanced filtering that is part of the specification”
so to be fair when you refer to and typed “MPEG4 derivative” above, to be accurate i the defenition for those that dont know, You actually mean an “MPEG4 PART2″ derivative, aka Divx/Xvid type codec .
the one before the MPEG4 part 10, aka AVC (advanced Video Codec), H.264 Yes ?
so in effect the current 2 year old plus commercial code that is now google VP8* is the bitstream specification, lets be clear as Dark Shikari points it out on the link, the actual currently released code is the specification… there never was a fully written text based bit-stream specification so no way to write a totally independent 3rd party VP8 Encoder for it.
So as people patch (including the x264 dev’s should they feel the will to write and port some POC to it) the current codebase They ARE by the very nature of a code based specification changing the core VP8 bit-stream specification ad-hock, it all sounds Very messy and all for the sub optimal codec that’s not as good as a generic x264 High Profile Encode as used everywhere by default.
why would you want a sub optimal visually fuzzy “baseline profile” at best when everyone’s perfectly capable of using a default High profile high Visual quality codec Encode in x264 Today and by all accounts x264 producing a lot smaller file size as an added default bonus for mobile users paying by the Kbit transferred bills Today ?
*(+generic Vorbis audio + renamed sub section of the full official Matroska container they are calling WebM)
#5 by tunnelled Multicast AVC - May 25th, 2010 at 19:37
hmm carlo as you say you have been a”representative at the European Working Group on Libre Software, the first EU initiative in support of Open Source and Free Software; chair the SME working group of the EU Task Force on Competitiveness,” etc
then you should know far better than to just copy a Lot of Dark Shikari’s copywrite’ed Text and Not provide a direct URL link back to that same text as a courtesy for providing You with your copy, the EU council take personal copywrite very seriously as you know
please provide that URL without delay for other readers to read and make their own minds up on the point you and he raise
http://x264dev.multimedia.cx/?p=377
#6 by cdaffara - May 25th, 2010 at 19:39
I tested it with a few videos from youtube. The webm version (of same quality, 720p) is smaller retaining the same quality. The Google Phone video for example: mp4 22M, webm 13M. Quality is quite similar, even on fast moving parts. So, what you write is actually not true. Do you have any example of videos that are much larger in webm? I just compiled an FFmpeg build to transcode things, will be happy to check it.
#7 by cdaffara - May 25th, 2010 at 20:02
Dear Tunnelled Multicast AVC, the link to the article is in the beginning of the phrase “Dark Shikari makes several considerations”. Due to a copy&paste it was not underlined and colored, but the link was there. I updated the style, so it shows; I made the same change for the Zdnet piece (it was blue but not underline). I
As for the rest of the comments: I highlighted in several points that x264 is at the moment the best H264 encoder out there, and probably one of the best encoders for all formats. You write: “thatŌĆÖs not as good as a generic x264 High Profile Encode as used everywhere by default. why would you want a sub optimal visually fuzzy ŌĆ£baseline profileŌĆØ at best when everyoneŌĆÖs perfectly capable of using a default High profile high Visual quality codec Encode in x264 Today and by all accounts x264 producing a lot smaller file size as an added default bonus for mobile users paying by the Kbit transferred bills Today ?”
Actually, as I wrote just a comment before, browsing youtube in webm (and downloading the bitstreams directly – go to the page source, search for the 720p streams, wget the mp4 and the webm versions) brings smaller files. The Google phone video is mp4 22M, webm 13M. Quality is similar, with no blur in static and moving areas.
And this is not actually a contest on what codec is better: the point is what codec is implementable in an open source way. x264 is a beautiful piece of code, but it actually is not free software in the sense that unless you have an MPEGLA license, you are not allowed to use it (legally) in countries that have granted patents on its implementation. This means that it cannot be used in the US, Italy, France, Germany, and many other countries.
Last point, about specifications: actually, lots of standards emerged from a C implementation. I have been in ISO for a few years, and for a long time before actual “crystallization” the only specification for H264 was the source code reference implementation. This never stopped anyone, even before the finalization of the spec, from producing an H264 encoder and decoder.
#8 by tunnelled Multicast AVC - May 25th, 2010 at 20:29
You are actually aware that the Youtube HD MP4 recoded as you upload it content is using the older x264 codebase and probably “High profile” ?
you should/would have to ask Dark Shikari what version of the x264 codebase was used when Google commissioned him and other x264 dev’s.
if your/anyone’s going to do a fair test then you should be using a lossless set of files as your input for all tests, not some pre-coded older google/youtube downloaded x264 encode and providing the Exact command lines you used for them along side the direct URL to these original files and ouput , but you should already Know these basic facts
#9 by Relgorka Shantilla - May 26th, 2010 at 00:35
I do not have much time right now, so I will repost a block that I have written in another thread:
“The so-called “360p” shows VP8 consistently taking 30%-100% more bandwidth on YouTube, with much worse audio quality. The 720p ranges from -5% to +30% bandwidth, with roughly equal audio quality and marginally worse image quality. Especially bad are: “high-contrast mixed-color images”, “color gradients”, and “fast motion” (really any fast motion, but especially full-scene fast motion). When you see stepping or dithering in the gradients and fades, you are looking at the 1990′s all over again. VP8 HQ reminds me of Bink Video HQ.
“VLC’s WebM support is not perfect, but it uses very little CPU compared to Opera. I saw in another thread (desktopteam? the forum thread?) that the performance hit in Opera is very temporary while they test a better drawing interface. In VLC I did not see torn frames, so most of the *really* bad image problems are an issue with Opera’s development preview.
“I still intend to have a writeup of my own later this week, but here are a few clips I used for the comparison:
“http://www.youtube.com/watch?v=tQxbpryKKQo
“360p”11.5MB/20.9MB; “720p”44.3MB/62.3MB
Adriana Lima COMEBACK (very poor audio in VP8/360p)
“http://www.youtube.com/watch?v=EMs5pWce1y0
“360p”10.8MB/13.5MB; “720p”34.5MB/34.3MB (!)
BLUR – Danica Patrick (well it certainly is blurry)
“http://www.youtube.com/watch?v=IMS-gewLP44
“360p”16.6MB/38.9MB (!); “720p”56.5MB/77.0MB
Hot Chip – I Feel Better (grueling, x264 does much better)
*It is noteworthy that VP8 LQ takes nearly 2.5x the space!
“http://www.youtube.com/watch?v=8sFlBJ1Jk3w
“360p”26.5MB/48.8MB; “720p”95.9MB/108MB
Billy Joel – Piano Man HD (Audio problems crept in VP8 LQ)
*VLC choked and died on the VP8 HQ, I blame VLC for this”
-R
PS: I do grasp that the “360p” h264 files had a smaller base resolution, but they looked very similar to VP8 in fullscreen. This does not adequately explain the large gap in file sizes, or the atrociously poor audio in several VP8 LQ (360p) videos. Performance in fast motion only comes close with videos that were of poor quality to begin with. “I Feel Better” and “Adriana Lima COMEBACK” both demonstrate severe dithering in some places, and severe stepped gradients in other places, both under VP8. Bear in mind also that YouTube incorporates some of the most minimal and hardware-agnostic encoder settings, so even the 720p HQ should not have B-frames or other major advantages.
#10 by cdaffara - May 26th, 2010 at 07:26
Actually I still believe that most comments miss the point of the article altogether. I have no interest in comparing, quality-wise,
the best encoder in the market (x264) with a just released encoder for a totally different codec. As written in the post, at low bitrate
x264 wins with an enormous margin, independently of the facts that the encoding is done by Youtube, by command line or whatever.
As most people found, VP8 is more or less in line with h264 for higher resolution videos (+/- a percentage from 10% to 25%), with some
artifacting that may be related more to the encoder immaturity than specific codec design issues.
So, now that we have settled that this is not a beauty contest, we should point out the fact that, at least comparing Chrome nightly builds,
WebM HD clips are on average within the same quality level of H264 as encoded by youtube, are more or less at the same bitrate, and the
playback happens at slightly lower CPU usage.
That’s the point: not the fact that x264 is able to create, by command line, smaller or better quality files (I know it perfectly), but that it
is viable as a substitute of H264 for online video viewing. HD video, that is – it will need some time to improve lower bitrate encoding,
as the people from Theora already discovered and partially compensated.
#11 by Robert O’Callahan - May 27th, 2010 at 04:24
If the audio quality on Youtube is bad, it’s because of poor encoding, not Vorbis. Even Dark Shikari agrees that Vorbis is a very good audio codec.
#12 by Ghh - May 28th, 2010 at 10:25
Because everyone by your definition is the guys that see no problem being enslaved to stupid software patents that should not have been granted anyways.
#13 by Relgorka Shantilla - May 28th, 2010 at 18:30
Mr. Daffara, I do understand your perspective. On a PC, a decent implementation of VP8 will offer similar 720p performance in both data, CPU, and perceived quality. That’s great.
However, more and more hardware supports native decoding of H.264, with nearly zero CPU usage even on netbooks, and tolerable CPU usage on tablets and smartphones. If VP8 is a little more efficient in software, that still means that most ARM-based devices will choke and die on anything better than 360p.
This is where Google’s poor choice of default encoding comes in. With a small screen, you can’t see much difference between 360p and 720p; however you can certainly HEAR just fine. If YouTube’s recoding is poorly done, people will avoid webm because “The downloads are longer and the audio is crap.”
I fully grasp that ogg is a great audio codec, I use it myself; however YouTube is the largest measuring stick to place webm against H.264. It’s great that 720p VP8 looks and sounds as good as the most minimal and low-requirement x264 output, with about the same filesize. However desktop computers are very fast, and hardware-accelerated Flash video is coming. More and more PCs will be able to view 1080p/High Profile/B-Frames/Psycho-Visual-Opts. On the mobile side, battery life will suffer until someone figures out how to decode VP8 in hardware. Current problems include poor YouTube audio, and trying to download twice as much data over a 3G connection.
It’s not to say that webm is doomed, or that things will not improve. Many of us are just disappointed that On2 worked to build this for many years, and only has this much to show.
#14 by cdaffara - May 28th, 2010 at 20:56
You are addressing two separate concerns: embedded systems and youtube. Let’s take the first one: actually, most of what is described as “native decoding” is actually hardware assisted DCT, filtering, motion compensation and so on; implemented at the low level through a single chip that hides inside a manager core and a set of programmable DSP that implements the actual operation. Having seen the actual block structure of WebM (similar to that of MPEG4) I am quite sure that you will see very soon reprogrammed macro blocks that implement most of WebM in “hardware”. Look at the companies that pledged support for it: MD, ARM, Broadcom, Digital Rapids, Freescale, Logitech, Imagination Technologies, Marvell, MIPS Technologies, NVIDIA, Qualcomm, Texas Instruments and Intel. Basically ALL the silicon core providers; and (as said before) most of what is needed is recoding the firmware of the already developed chipsets. Ah, and most of the silicon in modern smartphones actually is NOT accelerating H264 decoding. As an example, my Nokia N97 mini drops frame badly even on small clips.
As for youtube, actually the few tests I have done with HD video (that are those actually encoded in webm at the moment) seem to indicate a more or less similar quality to H264, with similar or smaller size. At the moment WebM is not very competitive at small sizes, that’s why YouTube is encoding HD video with it.
#15 by Relgorka Shantilla - June 1st, 2010 at 19:52
So I guess we’ll see where it’s gone after a year’s time?
#16 by Chris Double - June 28th, 2010 at 14:39
The poor audio on YouTube WebM builds is due to YouTube using ffmpeg’s own Vorbis encoder which is known to be quite bad. See this thread:
https://groups.google.com/a/webmproject.org/group/webm-discuss/browse_thread/thread/7c38347e9c043620/f73568e60b10736b
#17 by Huston - June 29th, 2010 at 05:54
I dont see how any major software ever gets done when people have to worry about violating obscure patents for some programing algorithm that pretty much anyone can derive when asked to invent a algorithm that does what ever it was designed to do.
For me it is like patenting the strokes taken when painting a house. I cant go up and down , cause ms owns that and cant go left to right cause of apple and cant go right to left due to google.. “Does anyone own circle strokes? wtf do you mean mister miyagi owns the circle stroke?”
#18 by taltamir - July 10th, 2010 at 01:58
[quote]Actually, I understand perfectly the issue at hand: my point was that the specification and the encoder quality are unrelated, and a good quality encoder[/quote]
A fair point, but the very article you critique claimed that large portions of the “specification” is nothing more than bare C code, and that the same code is used for both the reference coder and decoder. As a result, there are bugs that are not shown in reference decoder due to occurring identically in both (some already found) which makes bugs PART of the spec (for said portions of the spec that are nothing but C code)
That being said, very good analysis on the patent issue, and it does show that they were working around patents.
#19 by cdaffara - July 10th, 2010 at 12:03
You are right. The article is quite critical of how the specification is written, but actually I believe that the author is unfairly critical of the release process. I have no interest in defending Google (they are able to do it themselves) but this “release, then correct or amend” was part of several MPEG specs as well. I heard Chris DiBona at LinuxTag claiming that they were interested in releasing it fast, and that they will apply corrections and improvements.
As for uncorrectable bugs in the specification, during my time at ISO (I had a few years in SC34 and JTC1) I saw my good share of bugs included directly in the specification…