Archive for category divertissements
About software forges
Posted by cdaffara in blog, divertissements on June 17th, 2010
I had the opportunity to talk a little bit with Dirk Riehle at LinuxTag about business models, collaboration and infrastructures, and one of the arguments was about software forges, like SourceForge or GForge. I would like to provide a little bit of overview of our discussion, along with my reasoning about the future of such forges.
First of all, I am a strong believer in the idea that forges were one of the important elements for the maturation and creation of a large scale market of users and developers of open source; forges provided free, simple and no-cost infrastructure for the basic necessities of a project, like file storage, CVS, mailing lists and so on. In this sense, forges also helped in discovering software, by providing basic taxonomies of software code, and comprehensive search facilities.
But two main aspects are in my opinion reducing the potential of forges for recent projects, namely distributed development and information dissemination. One of the important evolutions in code development has been the widespread adoption of distributed version control, through Git, Bazaar, Mercurial and (to a lesser extent) other minor solutions. Git, for example, substantially increased the productivity of projects like Wine, and provide a good management framework for large scale development by nearly independent group, like in the case of the Linux kernel.
The other aspect is related to information dissemination: what happens to a project is lost between bug tracking, mailing lists, forum (why the replication of features? how to find if something was already solved in some other place?); projects are difficult to interact one with the other, with the impossibility of tracking evolution of one project from another without passing from one person in the middle subscribed to both. And, as Dirk graciously conceded, managing or adapting a forge is a real nightmare ![]() I remember our past work in the Spirit forge (a healthcare-oriented forge, that used digital certificates to authenticate and sign code entered in the platform) and still got the shivers.
I remember our past work in the Spirit forge (a healthcare-oriented forge, that used digital certificates to authenticate and sign code entered in the platform) and still got the shivers.
For this reason, I believe that future forges will be structurally different from the current ones: they will be based on small, efficient pieces, for example a central Git repo, that is enhanced by external modules that subscribe to modifications in the code stream and provide this information to higher-level applications, that for example produce graphs or link each atomic action to a wiki or tracking system. By moving things from a monolithic tool to loosely coupled pieces, we can end up with something that is more “facebook-like” than forge like, with individual apps that provide for example code quality services (like Sonar) or visualization services. I am a strong believer in a publish-subscribe mechanism for this, for example through XMPP, because it allows to solve easily the problem of how to track strongly coupled projects. For example, if my code is dependent on an external project I can subscribe to its own code announcement strams, or issue streams, since the same issues will probably apply to my code as well; this without an explicit interaction, and with the opportunity to link issues to individual actions (commits, reports, etc.) that remain valid even if I fork the library, or act independently on modifications that will eventually be merged in a single tree. I believe that in the future the number of strong or weak coupling will increase, and this will seriously limit the capabilities of current forges.
Why HTML5&Co are better for browsers, and what is still missing
Posted by cdaffara in divertissements on May 27th, 2010
It seems that WebM captured the interest of many that were looking for a potential escape from the HTML5 video deadlock (h264 or theora); Google managed to create a potentially suitable alternative, that seems to be relatively risk-free in terms of patents, while providing reasonable overall quality (especially for the HD video range; at lower bitrate and resolution still needs substantial work). This reignited the flash/html5 war, spurred by Apple and its ban of everything Flash or Flash-like. I have read lots of comments ranging from the “flash will be with us forever” to “flash is already dead”. The dichotomy presented is false, for several reasons; I will try to highlight a few of the comments I received, along with my thoughts:
Flash player is on 98% of the internet-connected devices. While this may be true (I doubt it, as most smartphones are actually internet-connected, and Flash does not work there, or is such a sad joke that it should be left for when the kids are asleep), it does not work on the majority of new internet devices, that are either pads, ARM-based devices or systems where Flash has not a good enough performance. Google recently mentioned that they activate 100000 Android devices per day, Apple is more or less in the same range, and there is still no Flash there (t will be – but I still suspect that the experience will not be that good to make it usable). The Flash player is still slow and complex, and unless the technology changes radically, I suspect that it will be still quite slow (unless for single-window, tailored small games as Kongregate demonstrated recently).
Video is the only important thing. Actually, video is important, but Flash is much more than video. While HTML5 allows for some simple games to be created entirely in the browser, going much farther than PacMan is still difficult.HTML%, Canvas, WebGL, Javascript and much more need to go beyond what they provide today; the road seem to go there, but is not there yet.
Video is important, and H264 is the best thing that we have. H264 is a very good standard, and properly implemented (as an example, within the x264 encoder) is really among the state of the art. But – a small and unscientific comparison I performed yesterday seem to indicate that actually WebM is fast and simple, as previous claim by On2 indicated. The simplicity of the transforms and the linear structure should lend well to an embedded implementation, that is actually just a specialized coding on a collection of onboard DSPs.
Flash works well enough right now. Actually, no. The player duplicates most of what is already present within a modern browser: it comes with its own language (quite similar to JavaScript, actually), its own Just-in-Time compiler, its own widgets and interaction tools, its own video and canvas implementation, and moving/activating objects between the Flash boundary and the browser is akin to pull concrete blocks through a straw. Not only the replication of functionality prevents any optimization, but the presence of what is essentially an alien object with its own activity loop creates an endless string of difficulties whenever you need to integrate non-trivial multimedia content with non-flash objects. In fact, one of the reason for pushing open video within HTML5 is to have a much better user experience with lower CPU and resource usage; and as soon as YouTube forces people to use a WebM enabled browser to experience it better, you will see a much quicker adoption.
Most of the missing things are already being worked on, both in the JavaScript engines, within subprojects like Websockets, packages (be it Google-style packages for the web store, or Jar-like packages), video, audio and much more. There is one thing that is missing, and that will be probably be introduced soon: DRM. I know – DRM is a useless gimmick, that up to now has not demonstrated any capability to hinder unlicensed copying, and on the contrary seem to be quite effective at pissing people off.
The reality is that most content providers are requiring a form of DRM – be it effective or not – because this way they have a legal way to ask damages, using the DMCA or similar legislation that were introduced around the world. Yes, most current DRM schemes are not designed to be effective, but to provide a legal instrument. That’s why some video vendors insist that HTML5 is not suited for video distribution: because it does not have a protection form, that (even if easily avoidable) provides a tool to ask for damages and external authority control. I am quite confident that sooner or later, someone will introduce a DRM option to provide optional content protection; at that point, Flash or Silverlight will provide no substantial technical or business advantage, and will be on the contrary disadvantages, especially in up-and-coming platforms.
An analysis of WebM and its patent risk – updated
Posted by cdaffara in divertissements on May 25th, 2010
[I have updated the post below, with some considerations from the past similar initiative by Sun (now Oracle) of the Open Media Commons, that designed a codec based on enhancement of H261+]
There is a substantial interest on the recently released WebM codec and specification from Google, the result of open sourcing the VP8 SDK from the recently acquired company On2. It clearly sparked the interest of many the idea of having a reasonably good, open and freely redistributable codec for which the patents are freely licensed in a way that is compatible with open source and free software licensing; at the same time, the results of initial analysis by Dark Shikari (real name Jason Garrett-Glaser, the author of the extraordinary x264 encoder) and others seem to indicate that the patent problem is actually not solved at all.
I believe that some of the comments (especially in Dark Shikari’s post) are a little bit off mark, and should be taken in the correct context; for this reason, I will first of all provide a little background.
What is WebM? WebM is the result of the open sourcing of the VP8 encoding system, previously owned by On2 technologies. It is composed of three parts: the bitstream specification, the reference encoder (that takes an uncompressed video sequence and creates a compressed bitstream) and the reference decoder (that takes the compressed bitstream and generates a decoded video stream). I stress the word “reference” because this is only one of the possible implementations; exactly like the H264 standard, there are many encoders and decoders, optimized for different things (or of different quality). An example of a “perfect” encoder may be a program that generates all possible bit sequences, decodes them (discarding the non-conforming ones), compares with the uncompressed original video and retains the one with the highest quality (measured using PSNR or some other metric). It would make for a very slow encoder, but would find the perfect sequence; that is, the smallest one that has the highest PSNR; on the other hand, decoders differ in precision, speed and memory consumption, making it difficult to decide which is the “best”.
Before delving into the specific of the post, let’s mention two other little things: to the contrary of what is widely reported, Microsoft VC1 never was “patent free”. It was free for use with Windows, because Microsoft was assumed to have all the patents necessary for its implementation; but as VC1 was basically an MPEG4 derivative, most of the patents there applies to VC1 as well, plus some other that were found later for the enhanced filtering that is part of the specification (and that were also part of the MPEG4 Advanced profile and H264). It was never “patent free”, it was licensed without a fee. (that is a substantially different thing – and one of the reasons for its disappearance. MS pays the MPEG-LA for every use of it, and receives nothing back, making it a money-loss proposition…)
Another important aspect is the prior patent search: it is clear (and will be evident a few lines down) that On2 made a patent search to avoid specific implementation details; the point is that noone will be able to see this pre-screening,to avoid additional damages. In fact, one of the most brain damaged things of the current software patent situation is the fact that if a company performs a patent search and finds a potential infringing patent it may incur in additional damages for willful infringement (called “treble damages”). So, the actual approach is to perform the same analysis, try to work around any potential infringing patent, and for those “close enough” cases that cannot be avoided try to steer away as much as possible. So, calling Google out for releasing the study on possible patent infringement is something that has no sense at all: they will never release it to the public.
So, go on with the analysis.
Dark Shikari makes several considerations, some related to the implementation itself, and many related to its “patent status”. For example: “VP8’s intra prediction is basically ripped off wholesale from H.264″, without mentioning that the intra prediction mode is actually pre-dating H264; actually, it was part of Nokia MVC proposal and H263++ extensions published in 2000, and the specific WebM implementation is different from the one mentioned in the “essential patents” of H264 as specified by the MPEG-LA.
If you go through the post, you will find lots of curious mentions of “sub-optimal” choices:
- “i8×8, from H.264 High Profile, is not present”
- “planar prediction mode has been replaced with TM_PRED”
- “VP8 supports a total of 3 reference frames: the previous frame, the “alt ref” frame, and the golden frame”
- “VP8 reference frames: up to 3; H.264 reference frames: up to 16″
- “VP8 partition types: 16×16, 16×8, 8×16, 8×8, 4×4; H.264 partition types: 16×16, 16×8, 8×16, flexible subpartitions (each 8×8 can be 8×8, 8×4, 4×8, or 4×4)”
- “VP8 chroma MV derivation: each 4×4 chroma block uses the average of colocated luma MVs; H.264 chroma MV derivation: chroma uses luma MVs directly”
- “VP8 interpolation filter: qpel, 6-tap luma, mixed 4/6-tap chroma; H.264 interpolation filter: qpel, 6-tap luma (staged filter), bilinear chroma”
- “H.264 has but VP8 doesn’t: B-frames, weighted prediction”
- “H.264 has a significantly better and more flexible referencing structure”
- “having as high as 6 taps on chroma [for VP8] is, IMO, completely unnecessary and wasteful [personal note: because smaller taps are all patented
 ]“
]“ - “the 8×8 transform is omitted entirely”
- “H.264 uses an extremely simplified “DCT” which is so un-DCT-like that it often referred to as the HCT (H.264 Cosine Transform) instead. This simplified transform results in roughly 1% worse compression, but greatly simplifies the transform itself, which can be implemented entirely with adds, subtracts, and right shifts by 1. VC-1 uses a more accurate version that relies on a few small multiplies (numbers like 17, 22, 10, etc). VP8 uses an extremely, needlessly accurate version that uses very large multiplies (20091 and 35468)”
- “The third difference is that the Hadamard hierarchical transform is applied for some inter blocks, not merely i16×16″
- “unlike H.264, the hierarchical transform is luma-only and not applied to chroma “
- “For quantization, the core process is basically the same among all MPEG-like video formats, and VP8 is no exception (personal note: quantization methods are mostrly from MPEG1&2, where most patents are already expired – see the list of expired ones in MPEG-LA list)”
- “[VP8 uses] … a scheme much less flexible than H.264’s custom quantization matrices, it allows for adjusting the quantizer of luma DC, luma AC, chroma DC, and so forth, separately”
- “The killer mistake that VP8 has made here is not making macroblock-level quantization a core feature of VP8. Algorithms that take advantage of macroblock-level quantization are known as “adaptive quantization” and are absolutely critical to competitive visual quality” (personal note: it is basically impossible to implement adaptive quantization without infringing, especially for patents issued after 2000)
- “even the relatively suboptimal MPEG-style delta quantizer system would be a better option. Furthermore, only 4 segment maps are allowed, for a maximum of 4 quantizers per frame (both are patented: delta quantization is part of MPEG4, and unlimited segment maps are covered)”
- “VP8 uses an arithmetic coder somewhat similar to H.264’s, but with a few critical differences. First, it omits the range/probability table in favor of a multiplication. Second, it is entirely non-adaptive: unlike H.264’s, which adapts after every bit decoded, probability values are constant over the course of the frame” (probability tables are patented in all video coding implementations, not only MPEG-specific ones, as adapting probability tables)
- “VP8 is a bit odd… it chooses an arithmetic coding context based on the neighboring MVs, then decides which of the predicted motion vectors to use, or whether to code a delta instead” (because straight delta coding is part of MPEG4)
- “The compression of the resulting delta is similar to H.264, except for the coding of very large deltas, which is slightly better (similar to FFV1’s Golomb-like arithmetic codes”
- “Intra prediction mode coding is done using arithmetic coding contexts based on the modes of the neighboring blocks. This is probably a good bit better than the hackneyed method that H.264 uses, which always struck me as being poorly designed”
- residual coding is different from both CABAC and CAVLC
- “VP8’s loop filter is vaguely similar to H.264’s, but with a few differences. First, it has two modes (which can be chosen by the encoder): a fast mode and a normal mode. The fast mode is somewhat simpler than H.264’s, while the normal mode is somewhat more complex. Secondly, when filtering between macroblocks, VP8’s filter has wider range than the in-macroblock filter — H.264 did this, but only for intra edges”
- “VP8’s filter omits most of the adaptive strength mechanics inherent in H.264’s filter. Its only adaptation is that it skips filtering on p16×16 blocks with no coefficients”
What we can obtain from this (very thorough – thanks, Jason!) analysis is the fact that from my point of view it is clear that On2 was actually aware of patents, and tried very hard to avoid them. It is also clear that this is in no way an assurance that there are no situation of patent infringements, only that it seems that due diligence was performed. Also, WebM is not comparable to H264 in terms of technical sophistication (it is more in line with MPEG4/VC1) but this is clearly done to avoid recent patents; some of the patents on older specification are already expired (for example, all France Telecom patents on H264 are expired), and in this sense Dark Shiraki claims that the specification is not as good as H264 is perfectly correct. It is also true that x264 beats the hell on current VP8 encoders (and basically every other encoder in the market); despite this, in a previous assessment Dark Shiraki performed a comparison of anime (cartoon) encoding and found that VP7 was better than Apple’s own H264 encode – not really that bad.
{kind=link}
The point is that reference encoders are designed to be a building block, and improvement (in respect of possible patents in the area) are certainly possible; maybe not reaching the level of x264 top quality (I suspect the psychovisual adaptive schema that allowed such a big gain in x264 are patented and non-reproducible) but it should be a worthy competitor. All in all, I suspect that MPEGLA rattling will remain only noise for a long, long time.
Update: many people mentioned in blog posts and comments that Sun Microsystem (now Oracle) in the past tried a very similar effort, namely to re-start development of a video codec based on past and expired patents, and start from there avoiding active patents to improve its competitiveness. They used the Open Media Commons IPR methodology to avoid patents and to assess patent troubles, and in particular they developed an handy chart that provides a timeline of patents and their actual status (image based on original chart obtained here):
{kind=link}
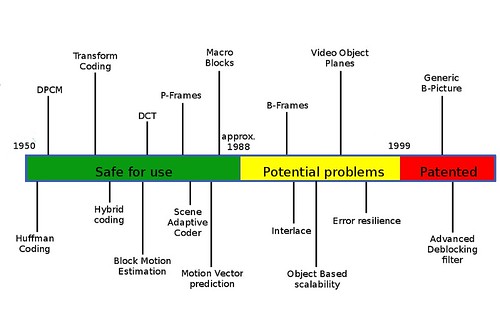
As it can be observed, most of the techniques encountered in the OMV analysis are still valid for VP8 (the advanced deblocking filter of course is present in VP8, but with a different implementation). It also provides additional support to the idea that On2 developers were aware of patents in the area, and came out with novel ideas to work around existing patents, much like Sun with its OMV initiative. In the same post, the OMV block structure graph includes several “Sun IPR” parts, that are included in the OMV specification (the latest version available here (pdf) – the site is not updated anymore) and that maybe may be re-used, with Oracle explicit permission, in WebM. And to answer people asking for “indemnification” from Google, I would like to point my readers to a presentation of OMV and in particular to slide 10: “While we are encouraged by our findings so far, the investigation continues and Sun and OMC cannot make any representations regarding encumbrances or the validity or invalidity of any patent claims or other intellectual property rights claims a third party may assert in connection with any OMC project or work product.” This should put to rest the idea that Sun was indemnifying people using OMV, exactly like I am not expecting such indemnification from Google (or any other industry player, by the way).
A small and unscientific exploration of OSS license use
Posted by cdaffara in OSS data, divertissements on March 17th, 2010
I was intrigued by an excellent (as usual) post by Matthew Aslett of 451 group, titled “On the fall and rise of the GNU GPL“, where Matthew muses on the impact of cloud computing and other factors in the decreasing role of the GPLv2 versus other type of licenses. Simon Phipps twitted “you only consider number of projects and not volume of deployed code. I have never found number of projects compelling” which is something that I absolutely believe is true: it is, however, quite difficult to imagine other possible ways to measure “impact” of a project. Do we have to add a weight related to usage? Then, given the large use of Linux, GNOME or KDE, OpenOffice, Firefox we would probably see a huge jump in the GPL and MPL percentages, at the cost of added uncertainty (as usage estimates are variable at best). As I am desperately try to avoid doing real work, I started using the Ohloh web site to extract slightly less than 100 projects (among the “active” ones, so there is already an initial preselection), along with the licensing and the number of committers for each project. My idea was to measure not only the number of projects, but how many people contributes to each, to see if this scenario gives different percentages. In a sense, the number of committers is a measure of “activity” or community interest in a project, and so my idea was to see if there was a difference between the percentages obtained with only the amount of projects listed under a license, and the number of committers using a license. The result is this:
| license | projects | committers | %projects | %committers | blackduck % |
| gpl2 | 49 | 15878 | 52.1% | 62.9% | 48.83 |
| lgpl | 8 | 2286 | 8.5% | 9.1% | 9.35 |
| mit | 6 | 1668 | 6.4% | 6.6% | 4 |
| bsd | 8 | 1150 | 8.5% | 4.6% | 6.26 |
| gpl3 | 3 | 988 | 3.2% | 3.9% | 5.5 |
| php | 2 | 730 | 2.1% | 2.9% | 0.24 |
| cddl | 1 | 673 | 1.1% | 2.7% | 0.32 |
| mpl | 2 | 655 | 2.1% | 2.6% | 1.22 |
| apache | 10 | 557 | 10.6% | 2.2% | 4.02 |
| boost | 1 | 266 | 1.1% | 1.1% | |
| epl | 2 | 241 | 2.1% | 1.0% | 0.46 |
| python | 1 | 133 | 1.1% | 0.5% | |
| cpl | 1 | 6 | 1.1% | 0.0% | 0.56 |
The result is interesting: first of all, by looking in terms of contributors, the GPLv2 has an higher percentage of committers than that of projects; that is, there are more committers per project under the GPLv2 in respect to the normal share. The percentage of projects obtained is similar to that from BlackDuck (52.1% versus 48.83%), so I think that there is not too much bias in the choice of projects. The LGPL has more or less its fair share of committers, on a par with the number of projects and the results from BlackDuck. MIT is slightly higher, both in projects and commits, while the GPLv3 is under-represented – probably because the sample is too small, and in the project selection the “new” projects under the GPLv3 simply were not among the first 100 or so selected. A substantial difference exist for Apache-licensed projects, where the average number of committers seems smaller than its fair share; this may be an artefact of the project selected, or may be simply an effect of how Ohloh measures the active committers (I find strange that Boost has half of all the committers of all the Apache projects together!)
As I said, this is a little, unscientific experiment designed to explore what we can invent to better measure the “impact” of an OSS project. I would love to receive you comments and suggestions; on my side, I will try to leverage the FLOSSMETRICS database to try to find some numbers on a more consistent data sample.
The H264 codec problem, or: we should find a better way
Posted by cdaffara in blog, divertissements on January 26th, 2010
I followed with great interest the intense debate on the initial HTML5 experiments of YouTube; given the prominent role of the video site in overall Flash usage, this has been heralded by some as a shining endorsement of HTML5, while others found its use of the H264 codec a sort of betrayal of the spirit of openness behind HTML. The reality is this has very little to do with Flash, and is related more to the now-ubiquitous role of video; despite the continuous progress of Flash in terms of technology, the browser plugin still is the blame for substantial slowness, jerkyness and overall difficulties, especially with HD video. A deeply embedded video engine is capable of better interaction with the rest of the browser paint/repaint engine, is better integrated with the internal event loop and in general can provide a better user experience at a lower CPU count.
The use of H264 video was probably due to a combination of factors: first of all the fact that Google is already an MPEG-LA licenser, meaning that the added cost will probably be very low, but more important is the overall greater maturity in terms of encoder and decoders. In fact, I believe that Theora (in its more recent implementations) can provide comparable quality to H264, as was shown by Greg Maxwell, but the encoders still need to demonstrate that the excellent quality demonstrated in Greg’s encoding are maintained for a wide range of material; in this sense, I am quite sure that in the next few months the quality differential will become very small, up to the point where Theora and H264 are more or less technically equal.
The problem is all the material, already encoded as H264, that will need to be converted. And this means that it will never happens, as the cost of doing so is higher than the cost of buying a license for H264. What will happen is that, if Flash continues to be developed outside of the main browser code, more and more content providers will prefer to use HTML5 and the open standards because this way it will be easier to provide a better quality to end-users, increasing the number of potential viewers.
This does not means that Flash will go away (as much as I would love to), as most of the functionality that is offered (outside of video) is not directly replicable in a sensible way through other means. Gordon is capable of render level 1 codes, Gnash has some level 7 codes, but in general there is no realistic way to ask for all the websites and content developers to throw out all their flash toolchests and start using something else. And there is no chance in hell that Adobe will open source their plugin (due to IPR issues, mainly). What HTML5 can do at the moment is still not sufficient to replace ActionScript and the advanced graphics features of Flash; my hope is that the advantage of being integrated directly in the browser will make it easier for developers to start targeting standards that do have a free implementation.
(Disclaimer: I have been part of ISO JTC1 for a few years, and have been working on video codecs on commercial projects from 1999 to 2005)
ChromiumOS: a look in the code, and in the model (updated)
Posted by cdaffara in blog, divertissements on November 24th, 2009
The release of Google ChromiumOS was an event waited by industry analysts with significant anticipation, and the overall impression after the announcement was that it went out as a fizzle, and not a bang. Most comments were centered on the obvious shortcomings of this first pre-alpha release, the significant limits in the supported hardware, the reliance on networking for everything (especially the initial login), the over-reliance on Google services. And all the comments are right-and, at the same time, based on a general misperception of what can be a potential competitor for the most visible part of the IT infrastructure, namely the traditional desktop PC. I had the opportunity to explore the code, build my version, and in general to evaluate the release in the context of the UTAUT model of technology adoption, and I believe that the approach is sound and sensible, and will change the market even if it fails.
The first misconception is the idea that ChromiumOS was designed as a desktop OS competitor, despite the previous comments from Google spokespersons that the release would have been targeted towards a different market. The reality is that, even in ideal conditions and with technology prevalence (that is, the new technology is invariably and clearly superior to the old one) in presence of strong network effect and market prevalence NO alternative can supplant the incumbent in a short period of time, but can eventually grow its market in small percentage increments. This is especially true if the incumbent has pricing flexibility, that is it is possible to lower prices to fight back economic advantages, by moving the dead loss to some other market sector where there is less competition. This is what happened in the netbook market, with the possible loss of market space to Linux alternatives thwarted by lowering the pricing point of the offered operating system. Google makes with ChromiumOS a technological bet, that is a clear continuation of their overall strategy, and that has a serious potential to materialize.
It is not a desktop operating system. Desktop OS are full-featured, flexible, allow for unlimited installation of applications; on the other hand, ChromiumOS is a thin shell designed to run the Chrome browser as a single application. So, everyone expecting Google to save the idea of the Linux desktop has missed the fundamental point that it is not possible for anyone to fight for the desktop and win in a short amount of time, and without a massive monetary investment. But it is always possible to create a new market, and that’s exactly what Google is trying to do; similarly to when Apple launched the iPhone, very few believed that it would reach any substantial market share, forgetting that the iPhone was not a phone, but an execution platform – something different from all the previous smartphones, for which apps and web browsing were at most an afterthought.ChromiumOS resembles in this aspect Moblin (and shares much code with it) but in an even more radical way.
It requires little or no maintenance and support. What is the single highest source of costs for PCs? Management and support. OS patching and installation/reinstallation, fixing applications, installing and removing apps, checking for malware, identity management… the list can go on forever. The real innovation in ChromiumOS is the use of an upgradeable read-only code frame, clearly mimicking set-top boxes that can upgrade themselves OTA (over the air) for example from a satellite channel. ChromiumOS is capable of managing in a transparent and secure way this upgrade, handling securely interruptions and attacks. This, coupled with a totally encrypted local store, means that the hardware can be effectively thought as a purely ephemeral device that can substituted with limited configuration needs, and that large numbers of devices can be upgraded and managed without human intervention and in total security. Applications are embedded in web pages, and managed as web pages; so the maintenance and training requirements are limited.
It is not really tied into Google. Of course in this first release it heavily uses Google services for everything; but changing that is trivial. The authentication part is managed by a PAM module that can be easily swapped, and login completion (that actually turns your login name in a gmail account) is just a small modification of the SLiM login manager used by the OS to perform the initial login, and can be changed with a few lines of code. The same for the application list (the first icon on the top left of the screen), that is merely a hardwired URL – change it with your own portal address, and you get the same result without using Google. The only part that requires some work is the integration of Google SSO (through a complex cookie exchange mechanism); augmenting that with something like OpenSSO from Sun would not require more than a few days of work anyway.
It is not a SplashTop clone. There are several Linux-based instant-on environments, designed to be integrated inside of a flash BIOS; the most famous one is SplashTop, used in many motherboards and notebooks from Asus, Acer, HP, Sony and many others. The problem of this approach is that it is “fixed”: the image is difficult to update and upgrade, and this means that it rapidly loses appeal. ChromiumOS uses a trusted boot mechanism to ensure that upgrades are legitimate, but integrates it in a clean and smart way, making sure that the users will continuously be up to date.
It does require the net most of the time, but not always. The first login requires a working connection, but then the credentials are hashed and stored in a cache wallet, that allows to enter even in absence of a connection. If the pages allow for detached operation (using Gears, HTML5 persistent storage, or similar mechanisms) the system will work even without a connection. It is a stopgag solution, but is sensible: most of the time spent in desktop applications is centered on online services that are unusable without a connection, so it makes sense when considering the OS as something that is not competing in the same market as a traditional PC. Local, cached web applications may provide in the future more flexibility in this sense, but moch effort needs to be done to make it a worthwhile path. If we consider how people spend time on the PC, we can use the data from Wakoopa, that ublished recently a measurement of time spent per application on Windows, OSX and Linux, and shows that for example on Windows the time is spent with:
- Firefox (28.71%)
- Internet Explorer (6.88%)
- Google Chrome (6.62%)
- Windows Explorer (5.92%)
- Windows Live Messenger (4.25%)
- Opera (2.97%)
- Microsoft Office Word (2.51%)
- Microsoft Office Outlook (2.22%)
- World of Warcraft (1.45%)
- Skype (1.30%)
Apart from Microsoft Word, no other application can be used without a connection; at the same time, most of the applications may be supplanted by future versions of web applications, if the evolution around HTML and related standards continue at the current pace. For games, up-and-coming standards like WebGL and O3D may provide this in a “clientless” way; this is similar to the Quake Live game, that at the moment requires an additional plug-in but that may be potentially recoded using only those standards.
It integrates digital identities better than anyone else. You login once-then, everything just works. Enterprise users with large scale SSO systems sometimes encounter this, but is not that common in consumer and smaller companies, and is a great productivity tool. It is just the beginning: more sophisticated user interfaces are needed (this one for example would be great), but many companies (including Microsoft) are making great progresses in this direction.
It introduces a different model. Desktop PC are flexible, adaptable, usable without connectivity, complex, fragile, difficult to manage. Thin (bitmap-based, like RDP or ICA) clients are slightly easier to manage, require no support, require substantial infrastructure investments, cannot work detached, have marginally lower management costs. The model adopted by Google leverages the local computing power for rendering pages, reducing back-end costs; is simpler to manage, requires no support and can integrate through plug-ins (or browser functionalities) rich functionalities, like 3D (with WebGL and O3d) or native processing (through NaCL) but always within the context of web-delivered applications.
The future will be the final judge; after all, even if something is not successful directly, it may “seed” a future evolution that is capable of shaking the market substantially. The real impact of Negroponte’s OLPC was not the machine in itself (despite the boatloads of innovations contained within) but the re-framing of the netbook market; similarly, maybe it will be not ChromiumOS that will lead the change, but I believe that it is a bold statement – in fact, much bolder than the code that was released.
All the possible errors, in a single slide.
Posted by cdaffara in blog, divertissements on October 5th, 2009
I found this slide deck, from a very large and visible software company (that I will not name, leaving it as an the exercise for the reader); I believe that it was created to provide a clear response to many popular misconceptions on open source software. Unfortunately, it seems to collect in a single slide most of the myths and false assumptions that I have already mentioned in our past work within FLOSSMETRICS.

First of all, “zero cost” is something that may be true or not- it simply is not the defining attribute of open source software. At the same time, saying that proprietary software has “lower ongoing cost” is not overall true (and I have tons of independent confirmation of that), claiming that proprietary has more features is (as before) not universally true, saying that proprietary software maintains backward compatibility generated substantial laughter across the poor people here in the office that has to provide support to our commercial customers, claiming that proprietary is “more secure” recalled the recent attack against DNS claiming that it was poorly protected freeware.
Should I continue? Open standards, anyone? And the last one, implying that only proprietary software is based on managed development? Any commercial OSS vendor would happily dismiss this claim as untrue. Commitment on support? I believe that my fellow three readers would not encountering any difficulties in thinking about proprietary products that got bought and buried underground, or that simply got scrapped altogether.
Ah, I would happily send my guide to this fellow slide author, but I believe that probably this would not change this company views a single bit.
OSS: the real point is software control
Posted by cdaffara in blog, divertissements on September 30th, 2009
Ah, the morning aroma of a freshly brewed flame war… With our restless Matt Asay that sternly observes that in the free software/open source war, open source won and we are all the better for it. Of course, this joins the rack of those that consider Richard Stallman a relic of a passed era, or the thoughtful comments of my favourite thinker, Glyn Moody, or the pragmatic and reasoned views of Matthew Aslett of the 451 group.
If there is one thing that emerges clearly from all these discussions, is that fundamentalism is wrong. It is wrong when it is spelled “OSS is better”, it is wrong when it claims “Microsoft is better” without any reasoning. Because rational thinking should be the basis of discussion, not religion. This is not to say that religion or moral motivations are bad- but beliefs should be recognised beforehand, to avoid turning any discussion into a flame war. That’s why I may feel at ease in criticizing Stallman for what I perceive as personal attacks, and at the same time recognize the fact that without him and the GPL the free software and open source world would be much less developed and relevant.
My perspective is simple: every user, developer, administrator that depends on software (and basically everyone does, today) should think before using a software or service, and understand who control it, and if this “who” is not the user, what can happen. It is not just a question of “religious beliefs” but practical thinking: is the software yours? Does the service you are using gives you the opportunity of moving somewhere else? What happens if the developers are not going in the direction you need?
If we consider this as the basis for discussion, lots of arguments in the OSS/FS camp become much simpler. The crusade against software patents is a way of defending the rights of use of the end-user against arbitrary legal attacks; in this sense, the only real reason for being not happy of having something like Mono is not the fact that it is a Microsoft “standard”, but the fact that it is probably covered by unknown patents. The same thing applies for Flash- most people is dependent from a single company for what amounts as a platform, still not replicated by OSS alternatives (like Gnash) and in any case potentially covered by patents not only by Adobe, but by many other companies as well. The “victory of pragmatism” that Matt proclaims is not actually related to FS and OSS (that are the same exact thing) but the general overcoming of emotional based arguments, that is absolutely a positive thing.
But the “new pragmatism” should also be viewed with suspicion, exactly as the claims that free software is “better” without reason. I will make the example of Mono: now it is pushed as a way to overcome what is equally proprietary, that is Flash. What happens when Microsoft stops promoting it? It is OSS, s0 it can theoretically go on forever, but very few will risk infringing patents with it, and so it will remain more or less limited to those shops already using .NET elsewhere (thus having paid for the right of use), limiting its growth potential. The scenario is not so unbelievable, after the unveiling of a real Silverlight port to Moblin, that makes Mono more or less redundant. Some “open core” systems suffer of the same problem: the user is forced, by the proprietary part, to abide to whatever decision is made by the vendor, independently of what OSS license the “open” part is licensed with.
The uncritical embracing of online services is similarly flawed: what happens if the company goes bankrupt, or discontinue the service? If you use EC2, you can always create your own infrastructure using Eucalyptus and continue your work. Can you say the same of all the services that are being promoted right now? Can you get a complete copy of your data, move it somewhere else?
Control is what really matters, on-premise and online. Who, how such control is performed, what it may affects. You may prefer the ethical angle (like Stallman did) or the economic angle (like I do) but the end result is the same, exactly like free software and open source are the same. The critical aspect is being able to assess this control and weight if the lack of control is compensated by the features you get (which is reasonable) or what kind of risk are you accepting in exchange. You like the integrated set of features proposed by Microsoft? That’s good as long as you know that some of the actions that they did in the past were not exactly transparent, and that your control of their offering is very limited. You like Google? Good! Just understand what happens if Gmail does not work. You prefer open source? Good! But with the increased control you get with it, you also get responsibility and increased effort.
Always ask yourself: it is your software, or not? Think about it, and don’t let the question disappear from your mind, because your business may depend on it.
ChromeOS, Jolicloud, and web desktops
Posted by cdaffara in blog, divertissements on September 15th, 2009
There is very little that Google says that is not analyzed to death, and that sometimes leave people puzzled. The announcement of Google Chrome-OS, a Linux-based lean operating system designed to streamline the use of web-based applications (especially for NetBooks) left a few scratching heads in the blogosphere, and was promptly dismissed by Microsoft as irrelevant. It is true that examples of the same concept abound, like the nicely executed Jolicloud or the various Ubuntu netbook remixes; at the same time, the clout and market power of Google has of course an undeniable impact.
The interesting point is that more than the idea of a lean Linux desktop, the fact that an enhanced web browser (along with some additions like Flash, HTML5, Gears and whatever) can nowadays be considered an effective desktop replacement is something that just one or two years ago could have been considered heretic, and with good reasons. But now, I do most of my writing in Zoho (that is in terms of features much better than Google docs), I use my Zimbra web-based client, I have a java-applet for SSH and even a Quake Live account for the occasional fragfest.You can do video editing, play music, watch TV, code, and there is no doubt that the amount of things possible within a browser will only increase.
The interesting point is that having a web-based infrastructure provides an alternative to all-out virtualization, thanks to the almost stateless approach that is typical of HTTP; having most of the processing handled by the browser reduces the server-side costs of providing services of one order of magnitude or more, while facilitating things like high-availability and in general accessibility. Not only that, but application provisioning become something simple and comprehensible, easily enhanced by the various strong single-sign-on system that are now available (and open source, like OpenSSO).
The browser, along with the innumerable additions that are now used, has become a good enough platform for computing for the mythical 95% of the population-and the cost savings of using a transaction-based architecture when compared to desktop-based (and pixel-based) rendering makes it very clear that the approach will continue to be explored.
The announcement (and, I hope, near future release of ChromeOS) will not in itself mark a significant change in the landscape, at least not without a substantial support (for example, as part of the BIOS of netbooks) of hardware vendors and an increase in availability of cheap and unmetered (or nearly-unmetered) bandwidth. It may, however, create a co-marketing opportunity that can be leveraged by mobile and converged telcos, for a remotely-managed, secure and extremely cheap design. Such a design can be extremely effective for business users, that need security, manageability and independence – all through a standard web browser. And if traditional pixel-based remotization is still necessary for legacy applications, it is still possible to export them, safely tunneled in an HTTPS connection, through open protocols like SPICE or RDP (eventually compiling the viewer as a native client application, so it can be delivered safely along with the connection).
Even if ChromeOS is not successful, I believe that within 2 years the concept in itself will be so economically compelling that it will make desktop virtualization marginal at best.
A snippet of truth: Microsoft’s lawyers on patent trolls
Posted by cdaffara in blog, divertissements on August 18th, 2009
Something not related to FLOSSMETRICS or other research areas, but fun nevertheless: while reading the MSFT/i4i Memorandum Opinion and Order, I just caught the following snippet that in my opinion closes very efficiently the discussion about “patent trolls”, that is companies that ratchet patents to extract money from (potentially) infringing companies. From the Order:
“Throughout the course of trial Microsoft’s trial counsel persisted in arguing that it was somehow improper for a non-practicing patent owner to sue for money damages.” (p.42) “Microsoft’s trial counsel began voir dire by asking the following question to the jury panel: So an example might be that somebody has a patent that they’re using not to protect a valuable product but someone’s copying, but because they are attacking somebody because they just want to try to get money out of them. So it fits, for example, with the litigation question Mr. Parker asked. So if somebody felt that — let’s take this case for an example. If somebody felt that the patents were being used in a wrong way, not to protect a valuable product but a wrong way, could you find that patent invalid or noninfringed?”
and:
“THE COURT: I understand that you just told the jury if somebody was using the patent not to compete, that that was the wrong way to use the patent?
MR. POWERS: No, not to compete; just to get money, not to protect anything. That’s what I asked.”
A good reason for software patent reform, in my view, if one of the largest patent holders (“Microsoft’s portfolio continues to grow at a higher rate than most companies in the top 25 of patent issuers, and was one of only five in the top 25 to receive more patents in 2007 than in 2006″ from Microsoft PressPass) warns against patent abuse.