Archive for category OSS adoption
“Libre Software for Enterprises”: new issue of the European Journal for the Informatics Professional
Posted by cdaffara in OSS adoption, blog on August 21st, 2009
It is available online the new issue of UPGRADE, the European Journal for the Informatics Professional, edited by Jesús-M. González-Barahona, Teófilo Romera-Otero, and Björn Lundell. The monograph is dedicated to libre software, and I am grateful to the editors for including my paper on best practices for OSS adoption. This is not the first UPGRADE edition devoted to libre and free software – the june 2005 edition was about libre software as a research field, june 2006 centered on OSS licenses, december 2006 was devoted to the ODF format, and the december 2007 edition was centered on free software research, all extremely interesting and relevant.
DoD OSCMIS: a great beginning of a new OSS project
Posted by cdaffara in OSS adoption, blog on August 20th, 2009
OSCMIS is a very large web-based application (more than half a GB of code), created by the Defense Information Systems Agency of the US Department of Defense, and currently in use and supporting 16000 users (including some in critical areas of the world, like a tactical site in Iraq). It is written in ColdFusion8, but should be executable with minimal effort using a CFML open source engine like Ralio; it is currently using MSSQL, but there is already a standard SQL version alternative. The application implements, among others, the following functions:
- Balanced Scorecard—extensive balanced scorecard application implementing DISA quad view (strategy, initiatives, issues, and goals/accomplished graph) practice. Designed and built in house after commercial vendors didn’t feel it was possible to create.
- DISA Learning Management System. Enables fast, easy course identification and registration, with registration validation or wait listing as appropriate, and automated supervisory notifications for approvals. Educational Development Specialists have control as appropriate of course curricula, venues, funds allocation data, reporting, and more. Automated individual and group SF182’s are offered. Includes many other training tools for intern management and training, competitive training selection and management, mandatory training, mentoring at all levels, etc.
- Personnel Locator System—completely integrated into HR, Training, Security, and other applications as appropriate. System is accessible by the entire DISA public. PLS feeds the Global Address List.
- COR/TM Qualification Management—Acquisition personnel training and accreditation status and display. Tracks all DISA acquisition personnel and provides auto notification to personnel and management of upcoming training requirements to maintain accreditation and more. Designed and built in house after the Acquisition community and its vendors didn’t feel it possible to create.
- Action Tracking System—automates the SF50 and process throughout a civilian personnel operation.
- Security Suite—a comprehensive suite of Personnel and Physical Security tools, to include contractor management.
- Force Development Program—individual and group professional development tools for military members, to include required training and tracking of training status and more.
- Network User Agreement—automated system to gather legal documentation (CAC signed PDF’s) of network users’ agreements not to harm the government network they are using. Used by DISA worldwide.
- Telework—comprehensive telework management tool to enable users to propose times to telework, with an automated notification system (both up and down) of approval status.
- JTD/JTMD management—provides requirements to manage billets, personnel, vacancies, and realignments, plus more, comprehensively or down to single organizations.
- Employee On-Boarding Tool—automates and provides automated notification in sequence of actions needed to ensure that inbound personnel are processed, provided with tools and accounts, and made operational in minimal time.
- DISA Performance Appraisal System—automates the process of collecting performance appraisal data. Supervisors log in and enter data for their employees. This data is output to reports which are used to track metrics and missing data. The final export of the data goes to DFAS.
- ER/LR Tracking System—provides comprehensive tracking and status of employee relations/labor relations actions to include disciplinary actions and participants of the advance sick leave and leave transfer programs.
- Protocol Office–comprehensive event planning and management application to all track actions and materials in detail as needed to support operations for significant events, VIP visits, etc.
This is a small snippet of the full list – at the moment covering more than 50 applications; some are specific to the military world, while some are typical of large scale organizations of all kind (personnel management, for example). The open source release of OSCMIS is important for several different reasons:
- It gives the opportunity to reuse an incredible amount of work, already used and tested in production in one of the largest defence groups.
- It creates an opportunity to enlarge, improve and create an additional economy around it, in a way similar to the release of the DoD Vista health care management system (another incredibly large contribution, that spawned several commercial successes).
- It is an example of well studied, carefully planned release process; while Vista was released through an indirect process (a FOIA request that leaved the sources in the public domain and later re-licensed by independent groups) OSCMIS was released with a good process from the start, including a rationale for license selection from Lawrence Rosen, that acted as counsel to OSSI and DISA.
It cannot be underestimated the role of both people inside of DISA (like Richard Nelson, chief of the Personnel Systems Support Branch), John Weathersby of OSSI, and I am sure many others, in preparing such a large effort. This is also a good demonstration of good cooperation between a competence center like OSSI and a government agency, and I hope an example for similar efforts around the world. (By the way, other efforts from OSSI are worthy of attention, including the FIPS validation of OpenSSL…)
For more information: a good overview from Military IT journal, Government computer news, a license primer from Rosen (pdf), and the press package (pdf). The public presentation will be hosted by OSSI the first of september in Washington.
I am indebted to Richard Nelson for the kindness and support in answering my mails, and for providing additional documentation.
Some observations on licenses and forge evolution
Posted by cdaffara in OSS adoption, OSS business models, OSS data on August 12th, 2009
One of the activities we are working on to distract ourselves from the lure of beaches and mountain walks is the creation of a preliminary model of actor/actions for the OSS environment, trying to estimate the effect of code and non-code contributions and the impact of OSS on firms (adopters, producers, leaders – following the model already outlined by Carbone), and the impact of competition-resistance measures introduced by firms (pricing and licensing changes are among the possibility). We started with some assumptions on our own, of course; first of all, rationality of actors, the fact that OSS and traditional firms do have similar financial and structural properties (something that we informally observed in our study for FLOSSMETRICS, and commented over here), and the fact that technology adoption of OSS is similar to other IT technologies.
Given this set of assumptions, we obtained some initial results on licensing choices, and I would like to share them with you. License evolution is complex, and synthesis reports (like the one that is presented daily by Black Duck) can only show a limited view of the dynamics of license adoption. In Black Duck’s database there is no account for “live” or “active” projects, and actually I would suggest them to add a separate report for only the active and stable ones (3% to 7% of the total, and actually those that are used in the enterprise anyway). Our model predicts that in the large scale, license compatibility and business model considerations are the main drivers for a specific license choice; in this sense, our view is that for new projects the license choice is more or less not changed significantly in the last year, and that can be confirmed by looking at the new projects appearing in sourceforge, that maintain an overall 70% preference for copyleft licensing models (higher in some specialized forges, that reach 75%, and of course lower in communities like Codeplex). Our prediction is that license adoption follows a diffusion process that is similar to the one already discussed here:
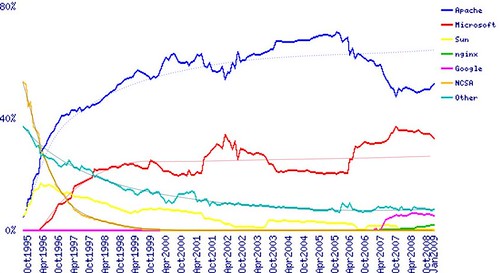
for web server adoption (parameters are also quite similar, as the time frame) and so we should expect a relative stabilization, and further reduction of “fringe” licenses. In this sense, I agree with Matthew Aslett (and the 451 CAOS 12 analysis) on the fact that despite the claims, there is actually a self-paced consolidation An important aspect for people working on this kind of statistical analysis is the relative change in importance of forges, and the movement toward self-management of source code for commercial OSS companies. A good example comes from the FlossMOLE project:
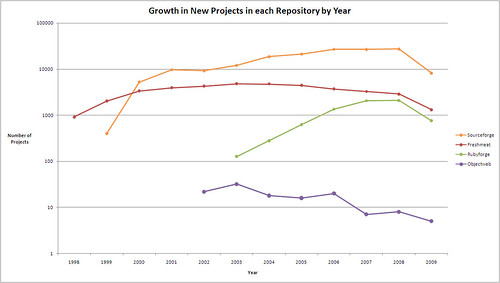
It is relatively easy to see the reduction in the number of new projects in forges, that is only partially offset by new repositories not included in the analysis like Googlecode or Codeplex; this reduction can be explained by the fact that with an increasing number of projects, it is easier to find an existing project to contribute to, instead of creating one anew. An additional explanation is the fact that commercial OSS companies are moving from the traditional hosting on Sourceforge to the creation of internally managed and public repositories, where the development process is more controlled and manageable; my expectation is for this trend to continue, especially for “platform-like” products (an example is SugarForge).
The different reasons for company code contributions
Posted by cdaffara in OSS adoption, OSS business models, OSS data on July 15th, 2009
It was recently posted by Matt Asay an intriguing article called “Apache and the future of open-source licensing“, that starts with the phrase “If most developers contribute to open-source projects because they want to, rather than because they’re forced to, why do we have the GNU General Public License?“
It turns out that Joachim Henkel (one of the leading European researchers in the field of open source) already published several papers on commercial contributions to open source projects, especially in the field of embedded open source. Among them, one of my favourite is “Patterns of Free Revealing – Balancing Code Sharing and Protection in Commercial Open Source Development“, that is available also at the Cospa knowledge base (a digital collection of more than 2000 papers on open source, that we created and populated in the context of the COSPA project). In the paper there is a nice summary analysis of reasons for contributing back, and one of the results is:
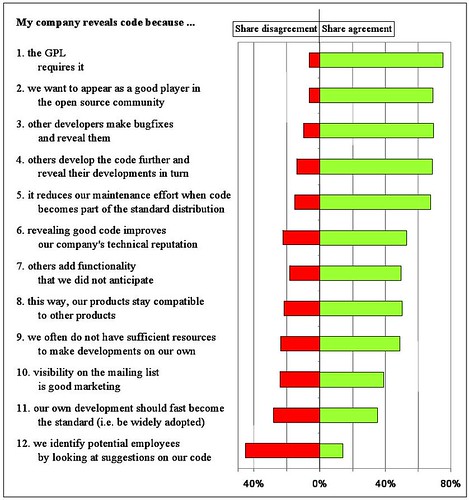
What does it means? That licensing issues are the main reason for publishing back, but separated by very few percentage points other reasons appear: the signaling advantage (being good players), the R&D sharing, and many others. In this sense, my view is that the GPL creates an initial context (by forcing the publication of source code) that creates a secondary effect – reuse and quality improvement – that appears after some time. In fact, our research shows that companies need quite some time to grasp the advantages of reuse and participation; the GPL enforces participation for enough time that companies discovers the added benefits, and start moving their motivations to economic reasons, as compared to legal enforcing or legal risks.
The new form of Open Core, or how everyone was right
Posted by cdaffara in OSS adoption, OSS business models, OSS data on July 9th, 2009
Right on the heels of the 451 group’s CAOS 12 report, I had the opportunity to perform a comparison between monetization modalities that we originally classified as open core in the first edition of our work with the more recent database of OSS companies and their adopted models (such an analysis can be found in our guide as well). An interesting observation was the shifting perspective on what open core actually is, and to present some examples on why I believe that the “original” open core nearly disappeared, while a “new” model was behind the more recent claims that this has become one of the preferred models for OSS companies.
In the beginning, we used as a classification criteria the distinction of code bases: an Open Core company was identified by the fact that the commercial product had a different source code base (usually an extension of a totally OS one), and the license to obtain the commercial was exclusive (so as to distinguish this from the “dual licensing” model). In the past, open core was more or less a re-enactment of shareware of old; that is, the open source edition was barely functional, and usable only to perform some testing or evaluation, but not for using in production. The “new” open core is more a combination of services and some marginal extension, that are usually targeted for integration with proprietary components or to simplify deployment and management. In this sense, the “real” part of open core (that is, the exclusive code) is becoming less and less important – three years ago we estimated that from a functional point of view the “old” open core model separated functions at approximately 70% (the OS edition had from 60% to 70% of the functions of the proprietary product), while now this split is around 90% or even higher, but is complemented with assurance services like support, documentation, knowledge bases, the certification of code and so on.
Just to show some examples: DimDim “We have synchronized this release to match the latest hosted version and released the complete source code tree. Bear in mind that features which require the Dimdim meeting portal (scheduling & recording to note) are not available in open source. There is also no limit to the number of attendees and meetings that can be supported using the Open Source Community Edition.” If you compare the editions, it is possible to see that the difference lies (apart from the scheduling and recording) in support and the availability of professional services (like custom integration with external authentication sources).
Alfresco: The difference in source code lies in the clustering and high-availability support and the JMX management extensions (all of which may be replicated with some effort by using pure OSS tools). Those differences are clearly relevant for the largest and most complex installations; from the point of view of services, the editions are differentiated through availability of support, certification (both of binary releases and of external stacks, like database and app server), bug fixing, documentation, availability of upgrades and training options.
Cynapse (an extremely interesting group collaboration system): The code difference lies in LDAP integration and clustering; the service difference lies in support, availability of certified binaries, knowledgebase access and official documentation.
OpenClinica (a platform for the creation of Electronic Data Capture systems used in pharmaceutical trials and in data acquisition in health care); from the web site: “OpenClinica Enterprise is fully supported version of the OpenClinica platform with a tailored set of Research Critical Services such as installation, training, validation, upgrades, help desk support, customization, systems integration, and more.”
During the compilation of the second FLOSSMETRICS database I found that the majority of “open core” models were actually moving from the original definition to an hybrid monetization model, that brings together several separate models (particularly the “platform provider”, “product specialist” and the proper “open core” one) to better address the needs of customers. The fact that the actual percentage of code that is not available under an OSS license is shrinking is in my view a positive fact: because it allows for the real OSS project to stand on its own (and eventually be reused by others) and because it shows that the proprietary code part is less and less important in an ecosystem where services are the real key to add value to a customer.
Conference announcement: SITIS09 track, Open Source Software Development and Solution
Posted by cdaffara in OSS adoption, OSS business models, blog on July 3rd, 2009
I am pleased to forward the conference announcement; I believe that my readers may be interested in the OSSDS track on open source development and solutions:
The 5th International Conference on Signal Image Technology
and Internet Based Systems (SITIS’09)
November 29 – December 3, 2009
Farah Kenzi Hotel
Marrakech, Morocco
http://www.u-bourgogne.fr/SITIS
In cooperation with ACM SigApp.fr, IFIP TC 2 WG 2.13, IEEE (pending)
The SITIS conference is dedicated to research on the technologies used to represent, share and process information in various forms, ranging multimedia data to traditional structured data and semi-structured data found in the web. SITIS spans two inter-related research domains that increasingly play a key role in connecting systems across network centric environments to allow distributed computing and information sharing.
SITIS 2009 aims to provide a forum for high quality presentations on research activities centered on the following tracks:
- The focus of the track “Information Management & Retrieval Technologies” (IMRT) is on the emerging modeling, representation and retrieval techniques
- that take into account the amount, type and diversity of information accessible in distributed computing environment. The topics include data semantics and ontologies, spatial information systems, Multimedia databases, Information retrieval and search engine, and applications.
- The track “Web-Based Information Technologies & Distributed Systems” (WITDS) is devoted to emerging and novel concepts, architectures and methodologies for creating an interconnected world in which information can be exchanged easily, tasks can be processed collaboratively, and communities of users with similarly interests can be formed while addressing security threats that are present more than ever before. The topics include information system interoperability, emergent semantics, agent-based systems, distributed and parallel information management, grid, P2P, web-centric systems, web security and integrity issues.
- The track “Open Source Software Development and Solution” (OSSDS) focuses on new software engineering method in distributed and large scaled environments, strategies for promoting, adopting, and using Open Source Solutions and case studies or success stories in specific domains. The topics include software engineering methods, users and communities’ interactions, software development platforms, open Source developments and project management, applications domain, case studies.
In addition to the above tracks, SITIS 2009 includes workshops; the final list of workshop will be provided later.
Submission and publication
————————–
The conference will include keynote addresses, tutorials, and regular and workshop sessions. SITIS 2009 invites submission of high quality and original papers on the topics of the major tracks described below. All submitted papers will be peer-reviewed by at least two reviewers for technical merit, originality, significance and relevance to track topics.
Papers must be up to 8 pages and follow IEEE double columns publication format. Accepted papers will be included in the conference proceedings and published by IEEE Computer Society and referenced in IEEE explore and major indexes.
Submission site : http://www.easychair.org/conferences/?conf=sitis09
Important dates
—————-
* Paper Submission: July 15th, 2009
* Acceptance/Reject notification: August 15th, 2009
* Camera ready / Author registration: September 1st, 2009
Local organizing committee (Cadi Ayyad University, Morocco)
————————————————————
* Aziz Elfaazzikii (Chair)
* El Hassan Abdelwahed
* Jahir Zahi
* Mohamed El Adnani
* Mohamed Sadgal
* Souad Chraibi
* Said El Bachari
Track Open Source Software Development and Solutions (OSSDS)
IFIP TC 2 WG 2.13
————————————————————-
The focus of this track is on new software engineering method for Free/Libre and Open Source Software (FLOSS) development in distributed and large scaled
environments, strategies for promoting, adopting, using FLOSS solutions and case studies or success stories in specific domains.
Software Engineering methods, users and communities interactions, software
development platforms:
* Architecture and patterns for FLOSS development
* Testing and reliability of FLOSS
* Software engineering methods in distributed collaborative environments
* Licencing and other legal issues
* Documentation of FLOSS projects
* CASE tool to support FLOSS development
* Agile principles and FLOSS development
* Mining in FLOSS projects
Applications domain, case studies, success stories:
* Geospatial software, services and applications
* Bioinformatics
* FLOSS for e-government and e-administration
* FLOSS in public sector (e.g. education, healthcare…)
* FLOSS solutions for data intensive applications
* FLOSS and SOA, middleware, applications servers
* FLOSS for critical applications
* FLOSS in Grid and P2P environments
* Tools and infrastructures for FLOSS development
* Scientific computing
* Simulation tools
* Security tools
Development and project management:
* Ecology of FLOSS development
* FLOSS stability, maintainability and scalability
* FLOSS evaluation, mining FLOSS data
* FLOSS and innovation
* Experiments, reports, field studies and empirical analysis
* FLOSS for teaching software engineering
* Revenue models
* Security concerns in using FLOSS
* Users involvement in design and development of FLOSS
* Building sustainable communities
Track Chairs
* Thierry Badard (University of Laval, Canada)
* Eric Leclercq (University of Bourgogne, France)
Program Committee
Abdallah Al Zain (Heriot-Watt University, UK)
Claudio Ardagna (Universita degli Studi di Milano, Italy)
Carlo Daffara (Conecta, Italy)
Ernesto Damiani (University of Milan, Italy)
Mehmet Gokturk (Gebze Institute of Technology, Turkey)
Scott A. Hissam (Carnegie Mellon University, USA)
Frédéric Hubert (University of Laval, Canada)
Puneet Kishor (University of Wisconsin-Madison and Open Source Geospatial
Foundation, USA)
Frank Van Der Linden (Philips, Netherlands)
Gregory Lopez (Thales group, France)
Sandro Morasca (Universita degli Studi dell’Insubria, Italy)
Pascal Molli (University of Nancy, France)
Eric Piel (University of Delft, The Netherlands)
Eric Ramat (University of Littoral, France)
Sylvain Rampacek (University of Bourgogne, France)
Marinette Savonnet (University of Bourgogne, France)
Charles Schweik, University of Massachussets, Amherst, USA)
Alberto Sillitti (University of Bolzano, Italy)
Megan Squire (Elon University, USA)
Marie-Noelle Terrasse (University of Bourgogne, France)
Christelle Vangenot (EPFL, Switzerland)
Just finished: the final edition of the SME guide to open source
Posted by cdaffara in OSS adoption, OSS business models, OSS data on July 2nd, 2009
It has been an absolutely enjoyable activity to work in the context of the FLOSSMETRICS project with the overall idea of helping SMEs to adopt, and migrate to, open source and free software. My proposed approach was to create an accessible and replicable guide, designed to help both those interested in exploring what open source is, and in helping companies in the process of offering services and products based on OSS; now, two years later, I found references to the previous editions of the guide in websites across the world, and was delighted in discovering that some OSS companies are using it as marketing material to help prospective customers.
So, after a few more months of work, I am really happy to present the fourth and final edition of the guide (PDF link) that will (I hope) improve in our previous efforts. For those that already viewed the previous editions, chapter 6 was entirely rewritten, along with a new chapter 7 and a newly introduced evaluation method. The catalogue has been expanded and corrected in several places (also thanks to the individual companies and groups responsible for the packages themselves) and the overall appearance of the PDF version should be much improved, compared to the automatically generated version.

I will continue to work on it even after the end of the project, and as before I welcome any contribution and suggestion.
A new way to select among FLOSS packages: the FLOSSMETRICS approach
Posted by cdaffara in OSS adoption, OSS business models on July 1st, 2009
One of the “hidden” costs of the adoption or migration to FLOSS is the selection process – deciding which packages to use, and estimating the risk of use when a project is not “mature” or considered enterprise-grade. In the COSPA migration project we found that in many instances the selection and evaluation process was responsible for 20% of the total cost of migration (including both the actual process, and the cost incurred in selecting the wrong package and then re-performing the assessment with a new one).
The problem of software selection is that there is a full spectrum of choices, and a different attitude to risk – a research experiment may be more interested in features, while a mission-critical adoption may be more interested in the long-term survivability of the software they are adopting. For this reason many different estimating methods were researched in the past, including EU-based research projects (the QSOS method, SQO-OSS, QUALOSS) and business-oriented systems like OpenBRR or the Open Source Maturity Model of CapGemini. The biggest problem of those methods is related to the fact that the non-functional assessment (that is, estimating the “quality” of the code and its community and liveness) is a non-trivial activity, that involves the evaluation and understanding of many different aspects of how FLOSS is produced.
For this reason we have worked within the FLOSSMETRICS project on a new approach that is entirely automated, and based on automated extraction of the “quality” parameters from the available information on the project (its repository and mailing lists). The first result is a set of significant variables, that collectively give a set of quality indicators of the code and the community of developers around the project; these indicators will be included in the public database of projects, and will give a simple “semaphore”-like indication of what aspects may be critical and what are the project strengths.
On the other hand we have worked on the integration of the functional aspects in the evaluation process – that is, how to weight in features vs. the risk that the project may introduce. For this reason we have added to our guide a new, simplified evaluation schema, that includes both aspects in a single graph.
Creating a graph for a product selection involves three easy steps:
- starting from the list of features, extract those considered to be indispensable from the optional ones; all projects lacking in indispensable features are excluded from the list.
- for every optional feature a +1 score is added to the project “feature score”, obtaining a separate score for each project.
- using the automated tools from FLOSSMETRICS, a readiness score is computed using the following rule: for every “green” in the liveness and quality parameters a +1 score is added, -1 for every “red”.
This gives for each project a position in a two-dimensional graph, like this one:
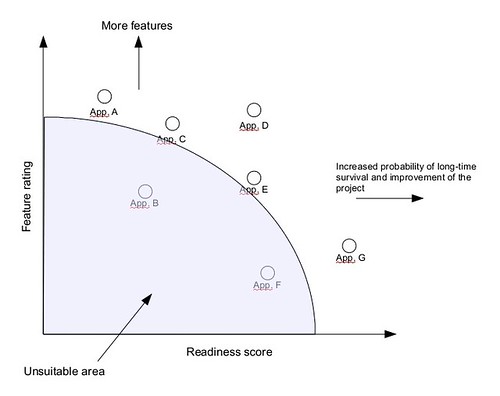
The evaluator can then prioritize the selection according to the kind of adoption that is planned: those that are mission-critical and that requires a high project stability (and a good probability that the project itself is successful and alive) will prefer the project positioned on the right-hand of the graph, while those that are more “experimental” will favour the project placed in the top:

This approach integrates the advantage of automated estimation of quality (and can be applied to the FLOSSMETRICS parameters or the previous QSOS ones) with a visual approach that provides in a single image the “risk” or inherent suitability of a set of projects. I hope that this may help in reducing that 20% of cost that is actually spent in deciding which package to use, thus improving the economic effectiveness or freeing more resources for other practical activities.
Freeriding, participation and another modest proposal
Posted by cdaffara in OSS adoption, OSS business models on June 10th, 2009
There has been in the past several articles related to “freeriding“, that is the use of OSS without any apparent form of reciprocal contribution, be it in a monetary form, or in terms of source code. I am not sympathetic to this view in general, because it masks an ill-posed question, that is “if you use someone code, are you required to give something back?”
It is in my view an ill posed question, because it mixes at the same level ethical and economic questions, and because it clearly avoids all the potential non-code contributions that are implicit in use, even in absence of back contributions. First of all, about ethical participation: open source code is available for all, without any form of implicit additional moral burden; the only rules that govern it are those that are laid out in the license itself. So, if the license for example allows for unconstrained use of a binary product derived from OSS code (for example, Eclipse) than it should not be expected from the majority of use any incremental contribution of any kind – it is simply not realistic to imagine that suddendly, all the Eclipse users should start contributing back because they are feeling guilty.
It is different when we think in economic terms, that is in terms of R&D sharing: in this frame of reference every user and potential contributors has an implicit model that gives a reason (or not) to contribute something, for example when there is an opportunity for reducing the cost of future maintenance by making it part of the official code base. This is a much more complex activity, because it requires first of all a high level of comprehension of the distributed development model that underlies most OSS projects, and then a clear and unambiguous path for contributing back something; this kind of contribution channel is clearly present only in some very high level and sophisticated projects, like the Eclipse consortium.
The second misunderstanding is related to the “hidden” role of users and non-code contributors. Most project (even our FLOSSMETRIC one) measure only code contributions – but this is just a small part of the potential contributions that may be provided. As the contributors map of OpenOffice.org shows:
There are many non-code contributions, like native language support, documentation, marketing, word-of-mouth dissemination, and so on. Even the fact that the software is used is a value: it can be for example used in marketing material for an eventual monetization effort, and is indirect demonstration of quality (the more users you have, the more inherent value the software may be inferred to be valuable for at least a category of users). I understand the gripes of commercial OSS vendors that would like to monetize every use of a software product, and discover that their software is used in some large company without giving back any monetary contribution. I took as an example Alfresco: “General Electric uses Alfresco’s software throughout the company while paying us nothing…and yet we’re having a banner year.” While I am sure that Matt Asay would love to have GE as a paying customer, even the reference is a proof of quality of Alfresco, and can be considered to be a valuable asset.
Users contribute back in terms of participation in forums, in providing direct and indirect feedback, and much more. Of course only a small part of the users contribute back, a phenomenon that was apparent in most social phenomenon well before the internet, and should be no surprise to anyone.
As a side note, as a continuation of my previous hypotesis on what may be the most efficient structure for maintaining the advantages of OSS resource sharing and proprietarization, I received many comments on the fact that most projects are small, and creating a full-scale Eclipse-like consortium (or something like OW2) is not really sustainable. But it is possible to imagine a OW2-like consortia that handles under its own umbrella the back-contribution to a large number of independent project, for each one managing the three core interactions (technical, social and legal) that are prerequisite for every completely verified contribution. Think about it: imagine yourself as a developer working in a company, and after some work the CEO allows for a linux-based product to be launched. As such, you make some patches and contributions, and instead of maintaining your own branch, you try to send back your patches. To who? Is it really that easy to discover the kernel mailing list? What is the proper form? If you need to send back patches to GCC (for example, for some embedded board processor) who do you contact? Is it really that easy to do? On the side of the project, how are contributions managed?
Each question is a stumbling block for a potential contribution. Of course, the larger project to have a channel – but sometimes it is not that easy to find and manage properly. I believe that an independent structure can increase the contribution process by providing:
- social skills: what is the proper contribution form? What groups and networks should be contacted?
- technical skills: what is the proper form? Is the contribution fulfilling the project internal rules for contribution?
- legal skills: has the contribution the proper legal attribution, has it been verified, has it been properly checked?
- marketing: show that software exist, that it can be used, and how.
Such a structure may be created for a limited cost, especially by leveraging the many voluntary activities that are now scattered in many individual projects. Instead of making yet another repositry, a local government could probably spend their money better in making sure that there is a realistic feedback channel. If this effort can increase the participation probability even by a small percentage, the potential return on investment is significant.
On OSS communities, and other common traps
Posted by cdaffara in OSS adoption, OSS business models on May 6th, 2009
Matt Asay just published a post titled “‘Community’ is an overhyped word in software“, where he collects several observations and basically states that ” Most people don’t contribute any software, any bug fixes, any blog mentions, or any anything to open-source projects, including those from which they derive considerable value. They just don’t. Sure, there are counterexamples to this, but they’re the exception, not the rule.” While true to some extent, the way the post is presented seems to imply that only commercial contributions are really of value (as he states later “So, if you want to rely on a community to build your product for you, good luck. You’re going to need it, as experience suggests that hard work by a committed core team develops great software, whether its Linux or Microsoft SharePoint, not some committee masquerading as a community.”)
This is somewhat true and somewhat false, and this dichotomy depends on the fact that “community” is an undefined word in this context. Two years ago I gave an interview to Roberto Galoppini, and one of the questions and answer was:
“What is your opinion about “the” community?
Alessandro [Rubini] is right in expressing disbelief in a generic “community”; there are organized communities that can be recognized as such (Debian or Gentoo supporters are among them) but tend to be an exception and not the rule. Most software do not have a real community outside of the developers (and eventually some users) of a single company; it takes a significant effort to create an external support pyramid (core contributors, marginal contributors, lead users) that adds value. If that happens, like in Linux, or the ObjectWeb consortium the external contributions can be of significant value; we observed even in very specialized projects a minimum of 20% of project value from external contributors.
I still believe that by leaving the underlying idea of “community” undefined Matt does collate together many different collaboration patterns, that should really not be placed together. In the mentioned example, the 20% was the result of an analysis of contribution to the OpenCascade project, a very specialized CAD toolkit. As I mention in my guide: “In the year 2000, fifty outside contributors to Open Cascade provided various kinds of assistance: transferring software to other systems (IRIX 64 bits, Alpha OSF), correcting defects (memory leaks…) and translating the tutorial into Spanish, etc. Currently, there are seventy active contributors and the objective is to reach one hundred. These outside contributions are significant. Open Cascade estimates that they represent about 20 % of the value of the software.” In a similar way, Aaron Seigo listed the many different ways “contribution” are counted in KDE, and noticed how those contributions are mostly not code-based:
- Artwork
- Documentation
- Human-computer interaction
- Marketing
- Quality Assurance
- Software Development
- Translation
Or take the contributors area map from OpenOffice.org:
While the yellow area is code-related, lots of other contributors are outside of that, and help in localization, dissemination, and many other ancillary activities that are still fundamental for the success of a project.
The Packt survey that Matt mentions is explicit in the kind of contribution it was mentioned: “Despite this apparent success, individual donations play an important role in its development. Its team still maintains a page on the project website requesting monetary donations, which they utilize for the promotion of phpMyAdmin. This highlights the importance of individual contributions and how they still play a vital role in sustaining and opening up open source projects to a larger audience.” This kind of monetary contribution is the exception, not the role, and using this data point to extend it to the fact that most projects are not dependent on external contributions (or do so in limited way) is an unwarranted logic jump.
I must say that I am more in agreement with Tarus Balog, that in his post (called, humorously, “sour grapes“) wrote: “The fact that marketing people can’t squeeze value out of community doesn’t mean that communities don’t have value… OpenNMS is a complex piece of software and it takes some intense dedication to get to the point where one can contribute code. I don’t expect anyone to sit down and suddenly dedicate hours and hours of their life working on it. Plus, I would never expect someone to contribute anything to OpenNMS unless they started out with some serious “free-loader” time.” This resonates with my research experience, where under the correct conditions communities of contributors provide a non-trivial benefit to the vendor; on the other hand, as we found in our previous FLOSSMETRICS research, monetization barrier can be a significant hurdle for external, disengaged participation, and this may explain why companies that use an “open core” or dual licensing model tend to see no external community at all. On the other hand, when community participation is welcomed and there is no “cross-selling”, external participations may provide significant added value to a project. A good example is Funambol (that has one of the best community managers I can think of), and a Twitter post I recently read about them: “HUGE contribution to !funambol MS Exchange connector from #mailtrust. Way to go, #community rocks“. Are commercial OS providers really interested in dismissing this kind of contributions as irrelevant?