Archive for category OSS business models
How to analyse an OSS business model – part three
Posted by cdaffara in OSS business models on March 1st, 2010
Welcome to the third part of our little analysis of OSS business models (first part here, second part here). It is heavily based on the Osterwalder model, and follows through the examination of our hypothetical business model reaching the “key resources” part. After all the theoretical parts, we will try to add a simple set of hands-on exercises and tutorials based on a more or less real case.
The argument of this part is “resources”. Key resources are the set of assets (material and immaterial) that are the basis of the company operations. There may be physical resources (a production plant for example), intellectual resources (previously developed source code), human resources (your developers), financial resources (capital in the bank, loans) and other immaterial assets (your company name as a recognizable mark, “good standing” in terms of how your customer see your products…)
In our OSS company example, at least part of the immaterial assets are shared and publicly available, that is they are non rival. In our model we have a company that provides under an open source license the community edition of the software, while provides an “enterprise edition” with additional stability tests, support and so on. It is not correct to say that just because the source code is publicly available it is not monetizable; on the contrary, especially when the code is wholly owned in terms of copyright assignments it is potentially a valuable asset (for some examples, look at JBoss or MySQL). Even when the code is cooperatively owned (as in a pure GPLv2 with multiple contributors, like Linux) the “default place” is valuable in itself, and it is the reason why so many companies try to make sure that their code is included in the main kernel line, thus reducing future integration efforts and sharing the maintenance activities. Other examples that are relevant for the OSS case are trademarks (that are sometimes vigorously defended), “brand name”, the external ecosystem of knowledge; for example, all the people that is capable of using and managing a complex OSS offering, creating a networked value that grows with the number of participants in the net. People becoming RedHat certified, for example, increases the value of the RedHat ecosystem other than their own.
One of the most important resource is human: the people working on your code, installing it, supporting it. Most of those people in the OSS environment are not part of your company, but are an extremely important asset on their own thanks to their capability of contributing back time and effort. In exchange, these resources need to be managed, and that’s why you need sometimes figures like “community managers” (an excellent example is my friend Stefano Maffulli, community manager extraordinaire at Funambol) because exactly as you have a financial officer to check your finance (another essential resource) you should have a community manager for… the community.
To properly analyse your key resources, we can extend the network model created for the channel analysis (the actor/action model) and extend it a little bit, including the missing pieces. For example, we mentioned that a potential customer may be interested in our product. Who makes it? Of course, as any good OSS company, you have some pieces coming from the outside (other OSS projects), part coded by your developers and part coming as contribution from external groups. All of them are resources: the other OSS projects are key resources themselves, simply obtained without immediate cost but managed by some developers that are themselves a key resources; your internally developed source code is another key resource, and if you have large scale contributions from the outside those should be considered resources too, maybe not “key” resources but important nevertheless.
The main concept is: a resource is “key” if without it your company would not be able to operate; and whenever you have a key resource you should have a person that manages it with a clearly defined process.
Next: cost structure!
How to analyse an OSS business model – part two
Posted by cdaffara in OSS business models on February 18th, 2010
(now available: part three)
Welcome to the second part of our little analysis of OSS business models (first part here). It is based on the practical workshops that we do for companies, and so it does have a little “practical” feel to it; as for its theoretical background, it is heavily based on the Osterwalder model, that I found to be clear and comprehensible. It could be adapted easily to other conceptualizations and ontologies on how to describe a business model, if someone wants to use it in a teaching context.
In the first part of our analysis we discussed the basic background concepts and discussed the first two aspects: customer segments and value proposition. As I mentioned before, the analysis is iterative, and should be done collaboratively (for example, by all the people working in a specific group, or by all the managers). As an example of why it should be iterative, we discussed the value proposition: by identifying several different value propositions, we inherently created different customer segments, that receive different value from our hypothetical “widgets, inc.” and this fact can be leveraged by differentiated pricing or different adoption percentages (if the user perceives an higher value, the potential monetary payment may be higher or it may be encouraged in adoption). Let’s continue with channels!
Channels: under this name we can place all the different ways our company interacts with the outside world. A common mistake is to consider only “paid” transactions, while (especially for open source software) a substantial part of value comes from non-monetary interactions. Examples of channel purposes may be sales, distribution (both physical and intangible), company communication, brand channelling and so on. Most channels do have a simple definition (“sales”) while some are indirect and outside the control of the company, for example word of mouth. As any iPhone user can testimony, word of mouth is one of the most powerful information dissemination vehicle, because it is based upon trust in people you already know, and knows what you may be interested in; the flash mob success of some online games on Facebook is a slightly modified version of this principle.
In channel analysis, the various actors in a company try to imagine (or list) all the possible ways someone from the outside may interact with the company or its products. How can a potential customer discover about widgets, inc. products? What actions need to be performed to be able to evaluate or buy? To help in this mapping exercise you can perform what is called the actor/actions mapping. In this activity you start by listing all the actors that may be potentially interacting with you, your users (potential or not), people that may talk about your product… Everything. You start with a simple table, listing the actors and the possible actions that they may want to perform. As an example:
- unaware user: casually finds out about widgets, inc. through advertising, word of mouth, email campaign…
- potential user: wants more information. Can go to the web site, download from a mirror site, ask friends, look for reviews of the product….
- user: wants support. Contact through email, phone, web-based system, (if there is a physical part) may ask for replacement of something…
- user: wants a different contract. As before, can use email, phone, a CRM system…
- journalist: may ask for information to write a review…
The idea is to try to map all the roles, all the actions, and list all of them along with a sort of small description. Then, imagine yourself while performing the action listed within: who do you interact with? What are the precondition for performing such action? As for the customer segmentation, you repeat this exercise until nothing changes, and at this point you have a nice, complete map of all the in/out relationships of widgets, inc. with the outside world. At that point, you add a value to each channel, in terms of what does it costs to maintain it and what potential advantage brings to you. It is important to bring to the table all potential value (even negative value, or intangible) because for open source software a large part of the channel network will not be directly managed by widgets, inc. but will be handled by third parties that cannot be directly influenced. So, a very simple example: Acme corp. takes the community edition of our software, adds some bells and whistles and creates a nice service business based on that. Is it a value or not? It does have a positive value: enlarges the use base, may provide additional contributions; on the other hand, it competes directly in at least part of the user base. The decision on how to act (the strategy part) depends on what we want to optimize, and is something that is inherently dynamic; so as an example what is good in the beginning (when dissemination of information and adoption is more important than monetization) may not be optimal in a later stage.
This is one of the explanation for the change in licensing by OSS companies, after an initial stage designed to maximize recognition and community contributions; among the examples Wavemaker. As I wrote many times in the past, there is no “bad” or “good” license, the point is that the license should be adopted with a rationale; changing license (when possible) may increase certain factors and modify in general this global channel map for example by changing the percentage of developers that are adopting our software, thanks to a more permissive license. The various parameters of our model (percentage of enterprise/community, independent adopters that integrate our software within their products, return contributions…) are all dependent on many different external conditions that are a-priori imposed by how we manage the company. So, after the creation of our channel map, an important exercise is to try to estimate these parameters, or measure them if possible; this way, we can turn our model into a simulation, giving us insight and allowing us to experiment freely to find the best match for our needs. We will give an example of such parameters after all the pieces of our business model canvas are completed.
Next time: key resources!
How to analyse an OSS business model – part one
Posted by cdaffara in OSS business models on February 17th, 2010
(now available: part two and three)
One of the activity that I love is teaching: especially, within companies, helping them to assess their business model, and improve it. The first part is analysis; from the dictionary definition, “to separate (a material or abstract entity) into constituent parts or elements; determine the elements or essential features of”. This separation is fundamental – lots of wrong choices are made because some of the underlying choices are done without a clear understanding of what the company do, how it does it, what pays and for what. I will give a small example of such an analysis session, using as a model the Osterwalder business model canvas, that can be found here:

Let’s start with an imaginary company, “widgets inc.”, that uses the “community/enterprise” model, that is a fully open source edition (usually called “community”) and an enterprise edition, that is released under a different license, and includes things like support and additional features. There are lots of vendors using this model, and as such it should be easy for my readers to imagine their own, favourite company listed.
The exercise is simple: we start by filling all the boxes, answering all the questions; the order that I suggest is: customer segments, value proposition, channels, key resources, cost structure, revenue streams and the rest in any order. Let’s start!
Customer segments: who we are selling to, or interact with? Let’s start with the initial concept that not all customers do have a commercial relationship with the company. Some may be using the community edition, but may be users as well; the fact that they are not paying (yet) does not imply that they are of no value for “widgets inc.” The company may have a single segment or many segments; some offerings may be unstructured (which is always a bad thing, as it means that the effort for producing an offer cannot be automated) or simply everything may be dumped in a single bucket. The idea is to start from the differences; that is, different channels, different relationships, different profitability, different willingness to pay – every time you have a difference, it should be reflected in a segmentation of your customers. In a lot of situation this is perceived as a useless effort – especially if the company offers a single product. But separating customers across all the different variables allows for something similar to sensitivity analysis; for example, is the directly contacted customer more or less profitable than the one acquired through an indirect channel? How much do we lose by going through an intermediary?
So, let’s imagine that our “widgets inc.” is selling directly and through a reseller network. Resellers are providing additional reach, thanks to their own marketing efforts, so we have at least 3 different segments: users of the community edition, users of the enterprise edition that have a direct relationship with widgets inc. and users of the enterprise edition that are managed by a partner. There is a potential fourth segment, that is users of a potential “community enhanced” edition, for example a commercial offering by an independent vendor that enhanced the community edition and that is selling that in a form similar to our enterprise offering”. What can we say of these segments? The enterprise edition users are paying us (of course) and the profitability of each customer depends on the cost of servicing it (that changes if we follow it directly or through a partner); a reseller will require a percentage of revenues, but on the other hand it handles some of the support costs, and covered some of the expenses for getting the customer in the first place. The community users are not paying us, but can be leveraged in several ways: as a reference (for example GE is an Alfresco user, even if it was not paying for the enterprise edition, and this can be a reference with a commercial value) and by conversion. In fact, community users may become enterprise users, with a conversion ratio that is quite low (from 0.5% to 3%, depending on the kind of software) but that can become substantial if the user base is large enough. MySQL is a good example of such “conversion by numbers”. Sometimes segments are interlocked, in what are called “multisided markets”. An example is a merchant like eBay, that needs a large number of buyers and sellers to guarantee the fluidity of the market itself; it may charge sellers, buyers or both, charge only on trade performed, on publication or not at all (for example, using advertising to recover costs).
A common segmentation is also that based on size or revenue assumptions, so you get something like an SME offering and a large company (or administration) offering. Thanks to data from eBusinessWatch (an observatory of the European Commission) we know that the average precentage of revenues spent for ICT in companies is roughly the same for small and large companies, but this does also imply that smaller companies do have a smaller available budget, while larger companies may have a much longer (and costlier) procurement process.
Value proposition: the reason why someone would want to come to widgets inc. in the first place, because we solve a problem or satisfy a need. In our case, we have two separate propositions: one for the community edition and one for the enterprise edition. The community edition may solve a practical problem for companies (for example, document management, groupware, whatever), and thus gives a concrete value in exchange for the time necessary for the customer to install and adapt the product by themselves, including the potential risk if something does not work. The enterprise edition changes this proposition, by costing something (in monetary term) in exchange for an easier installation or better out-of-the-box experience, support, lower risk (knowing that it is possible to ask for support) and so on. The value proposition should be explicit (to give your customers, paying and non-paying, an idea of why it is useful to invest time or money in widgets inc. products), realistic (your company will not survive in the long term if the value advantage is not there at all) and approximately quantifiable. The value proposition may be different for different customer segments, for example a groupware system for a small company may not require to handle thousands of users; in general, the additional value of a feature or a structural property of your product is dependent on whether your customer is in position to use it, and this usually shows out in the fact that there may be different advertising for different segments, pushing only on those features that are relevant.
Next part: channels and resources. See you next time!
Why COMmunity+COMpany is a winning COMbination
Posted by cdaffara in OSS adoption, OSS business models on October 16th, 2009
There is an interesting debate, partially moved by Matt Asay, with sound responses from Matthew Aslett, that centered on the reasons for (or not) moving part of the core IP asset of an open source company towards an externally controlled group, like a consortia. Matthew rightly indicates that this is probably the future direction of OSS (the “4.0″ of his graph), and I tried to address this with a few friends on twitter- but 140 chars are too few. So, I will use this space to provide a small overview of my belief: the current structure based on open core is a temporary step in a more appropriate commercialization structure, that for efficiency reason should be composed of a commuity-managed (or at least, transparently managed) consortia that manages the “core” of what now is the open source part of open core offerings, and a purely proprietary company that provides the monetization services, may those be proprietary add-ons, paid services and so on.
Why? Because the current structure is not the most efficient to enable participation from outside groups- if you look at the various open core offerings, the majority of the code is developed from in-house developers, while on community-managed consortia the code may be originated by a single company, but is taken up by more entities. The best example is Eclipse: as recently measured, 25% of the committers work for IBM, with individuals accounting for 22%, and a large number of companies like Oracle, Borland, Actuate and many others with percentages that go from 1 to 7% in a collective, non-IBM collaboration.
Having then a pure proprietary company that sells services or add-ons also removes any possibility of misunderstanding about what is offered to the customer, and thus will make the need of a “OSS checklist” unnecessary. Of course, this means that the direction of the project is no longer in the hand of a single company, and this may be a problem for investors- that may want to have some form of exclusivity or guarantee of maintaining the control. But my impression is that there is only the illusion of control, because if there is a large enough payoff, forks will make the point moot (exactly like it happened with MySQL); and by relieving control, the company gets back a much enlarged community of developers and potential adopters.
On licenses, communities, business models
Posted by cdaffara in OSS business models, OSS data on August 28th, 2009
The debate on whether the GPL is going the way of the dodo or not is still raging, in a way similar to the one on open core – not surprisingly, since they are both related to similar aspects, that intermingle technical and emotional aspects. A recent post from BlackDuck indicates that (on some metric, not very well specified unfortunately) the GPLv2 for the first time dropped below 50%; while Amy Stephen points out that the GPLv2 is used in 55% of the new projects (with the LGPL at 10%), something that is comparable to the results that we found in FLOSSMETRICS for the stable projects. Why such a storm? The reason is partly related to a strong association of the GPL with a specific political and ethical stance (an association that is, in my view, negative in the long term), and partly because the GPL is considered to be antithetic to so-called “open core” models, where less invasive licenses (like the Apache or Eclipse licenses) are considered to be more appropriate.
First of all, the “open core” debate is mostly moot: the “new” open core is quite different from the initial, “free demo” approach (as magistrally exemplified by Eric Barroca of Nuxeo). While in the past the open core model was basically to present a half-solution barely usable for testing now open core means a combination of services and (little) added code, like the new approach taken by Alfresco – that in the past I would have probably classified in the ITSM class (installation/training/support/maintenance, in recent report rechristened as “product specialist). Read as an example the post from John Newton, describing Alfresco approach:
- We must insure that customers using our enterprise version are not locked into that choice and that open source is available to them. To that end, the core system and interfaces will remain 100% open source.
- We will provide service and customer support that provides insurance that systems will run as expected and correct problems according our promised Service Level Agreement
- Enterprise customers will receive fixes as a priority, but that we will make these fixes available in the next labs release. Bugs fixed by the community are delivered to the community as a priority.
- We will provide extensions and integrations to proprietary systems to which customers are charged. It is fair for us to charge and include this in an enterprise release as well.
- Extensions and integrations to ubiquitous proprietary systems, such as Windows and Office, will be completely open source.
- Extensions that are useful to monitor or run a system in a scaled or production environment, such as system monitoring, administration and high availability, are fair to put into an enterprise release.”
The new “open core” is really a mix of services, including enhanced documentation and training materials, SLA-backed support, stability testing and much more. In this new model, the GPL is not a barrier in any way, and can be used to implement such a model without additional difficulties. The move towards services also explains why despite the claim that open core models are the preferred monetization strategies, our work in FLOSSMETRICS found that only 19% of the companies surveyed used such a model, a number that is consistent with the 23.7% found by the 451 group, despite the claim that “Open Core becomes the default business model”. The reality is that the first implementation of open core was seriously flawed; for several reasons:
“The model has the intrinsic downside that the FLOSS product must be valuable to be attractive for the users, but must also be not complete enough to prevent competition with the commercial one. This balance is difficult to achieve and maintain over time; also, if the software is of large interest, developers may try to complete the missing functionality in a purely open source way, thus reducing the attractiveness of the commercial version.”
and, from Matthew Aslett:
I previously noted that with the Open-Core approach the open source disruptor is disrupted by its own disruption and that in the context of Christensen’s law of Conservation of Attractive Profits it is probably easier in the long-term to generate profit from adjacent proprietary products than it is to generate profit from proprietary features deployed on top of the commoditized product.
In the process of selecting a business model, then, the GPL is not a barrier in adopting this new style of open core model, and certainly creates a barrier for potential freeriding by competitors, something that was for example recognized by SpringSource (that adopted for most of their products the Apache license):
The GPL is well understood by the market and the legal community and has notable precedents such as MySQL, Java and the Linux kernel as GPL licensed projects. The GPL ensures that the software remains open and that companies do not take our products and sell against us in the marketplace. If this happened, we would not be able to sufficiently invest in the project and everyone would suffer.
The GPL family, at the moment, has the advantage that the majority of packages are licensed under one of such licenses, making compatibility checking easier; also, there is an higher probability of finding a GPL (v2, v3, AGPL, LGPL) package to improve than starting for scratch – and this should also guarantee that in the future the license mix will probably continue to be oriented towards copyleft-style restrictions. Of course, there will be a movement towards the GPLv3 (reducing the GPLv2 share, especially for new projects) but as a collective group the percentages will remain more or less similar.
This is not to say that the GPL is perfect: on the contrary, the text (even in the v3 edition) lacks clarity on derivative works, has been bent too much to accommodate anti-tivoization clauses (that contributed to a general lack of readability of the text) and lacks a worldwide vision (something that the EUPL has added). In terms of community and widespread adoption the GPL can be less effective as a tool for creating widespread platform usage; the EPL or the Apache license may be more appropriate for this role, and this because the FSF simply has not created a license that fullfills the same role (this time, for political reasons).
What I hope is that more companies start the adoption process, under the license that allows them to be commercially sustainable and thriving. The wrong choice way hamper growth and adoption, or may limit the choice of the most appropriate business model. The increase in adoption will also trigger what Matthew Aslett mentioned as the fifth stage of evolution (still partially undecided). I am a strong believer that there will be a move toward consortia-managed projects, something similar to what Matthew calls “the embedded age”; the availability of neutral third-party networks increase the probability and quality of contributions, in a way similar to the highly successful Eclipse foundation.
Some observations on licenses and forge evolution
Posted by cdaffara in OSS adoption, OSS business models, OSS data on August 12th, 2009
One of the activities we are working on to distract ourselves from the lure of beaches and mountain walks is the creation of a preliminary model of actor/actions for the OSS environment, trying to estimate the effect of code and non-code contributions and the impact of OSS on firms (adopters, producers, leaders – following the model already outlined by Carbone), and the impact of competition-resistance measures introduced by firms (pricing and licensing changes are among the possibility). We started with some assumptions on our own, of course; first of all, rationality of actors, the fact that OSS and traditional firms do have similar financial and structural properties (something that we informally observed in our study for FLOSSMETRICS, and commented over here), and the fact that technology adoption of OSS is similar to other IT technologies.
Given this set of assumptions, we obtained some initial results on licensing choices, and I would like to share them with you. License evolution is complex, and synthesis reports (like the one that is presented daily by Black Duck) can only show a limited view of the dynamics of license adoption. In Black Duck’s database there is no account for “live” or “active” projects, and actually I would suggest them to add a separate report for only the active and stable ones (3% to 7% of the total, and actually those that are used in the enterprise anyway). Our model predicts that in the large scale, license compatibility and business model considerations are the main drivers for a specific license choice; in this sense, our view is that for new projects the license choice is more or less not changed significantly in the last year, and that can be confirmed by looking at the new projects appearing in sourceforge, that maintain an overall 70% preference for copyleft licensing models (higher in some specialized forges, that reach 75%, and of course lower in communities like Codeplex). Our prediction is that license adoption follows a diffusion process that is similar to the one already discussed here:
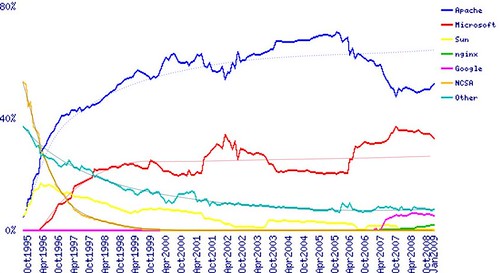
for web server adoption (parameters are also quite similar, as the time frame) and so we should expect a relative stabilization, and further reduction of “fringe” licenses. In this sense, I agree with Matthew Aslett (and the 451 CAOS 12 analysis) on the fact that despite the claims, there is actually a self-paced consolidation An important aspect for people working on this kind of statistical analysis is the relative change in importance of forges, and the movement toward self-management of source code for commercial OSS companies. A good example comes from the FlossMOLE project:
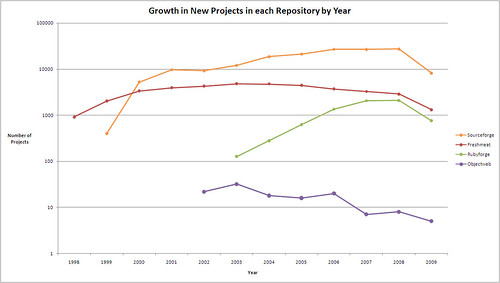
It is relatively easy to see the reduction in the number of new projects in forges, that is only partially offset by new repositories not included in the analysis like Googlecode or Codeplex; this reduction can be explained by the fact that with an increasing number of projects, it is easier to find an existing project to contribute to, instead of creating one anew. An additional explanation is the fact that commercial OSS companies are moving from the traditional hosting on Sourceforge to the creation of internally managed and public repositories, where the development process is more controlled and manageable; my expectation is for this trend to continue, especially for “platform-like” products (an example is SugarForge).
The different reasons for company code contributions
Posted by cdaffara in OSS adoption, OSS business models, OSS data on July 15th, 2009
It was recently posted by Matt Asay an intriguing article called “Apache and the future of open-source licensing“, that starts with the phrase “If most developers contribute to open-source projects because they want to, rather than because they’re forced to, why do we have the GNU General Public License?“
It turns out that Joachim Henkel (one of the leading European researchers in the field of open source) already published several papers on commercial contributions to open source projects, especially in the field of embedded open source. Among them, one of my favourite is “Patterns of Free Revealing – Balancing Code Sharing and Protection in Commercial Open Source Development“, that is available also at the Cospa knowledge base (a digital collection of more than 2000 papers on open source, that we created and populated in the context of the COSPA project). In the paper there is a nice summary analysis of reasons for contributing back, and one of the results is:
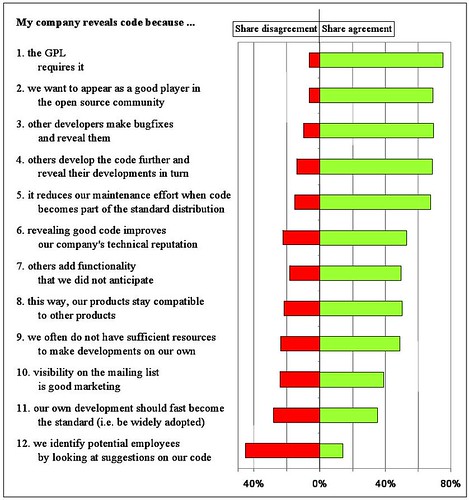
What does it means? That licensing issues are the main reason for publishing back, but separated by very few percentage points other reasons appear: the signaling advantage (being good players), the R&D sharing, and many others. In this sense, my view is that the GPL creates an initial context (by forcing the publication of source code) that creates a secondary effect – reuse and quality improvement – that appears after some time. In fact, our research shows that companies need quite some time to grasp the advantages of reuse and participation; the GPL enforces participation for enough time that companies discovers the added benefits, and start moving their motivations to economic reasons, as compared to legal enforcing or legal risks.
The new form of Open Core, or how everyone was right
Posted by cdaffara in OSS adoption, OSS business models, OSS data on July 9th, 2009
Right on the heels of the 451 group’s CAOS 12 report, I had the opportunity to perform a comparison between monetization modalities that we originally classified as open core in the first edition of our work with the more recent database of OSS companies and their adopted models (such an analysis can be found in our guide as well). An interesting observation was the shifting perspective on what open core actually is, and to present some examples on why I believe that the “original” open core nearly disappeared, while a “new” model was behind the more recent claims that this has become one of the preferred models for OSS companies.
In the beginning, we used as a classification criteria the distinction of code bases: an Open Core company was identified by the fact that the commercial product had a different source code base (usually an extension of a totally OS one), and the license to obtain the commercial was exclusive (so as to distinguish this from the “dual licensing” model). In the past, open core was more or less a re-enactment of shareware of old; that is, the open source edition was barely functional, and usable only to perform some testing or evaluation, but not for using in production. The “new” open core is more a combination of services and some marginal extension, that are usually targeted for integration with proprietary components or to simplify deployment and management. In this sense, the “real” part of open core (that is, the exclusive code) is becoming less and less important – three years ago we estimated that from a functional point of view the “old” open core model separated functions at approximately 70% (the OS edition had from 60% to 70% of the functions of the proprietary product), while now this split is around 90% or even higher, but is complemented with assurance services like support, documentation, knowledge bases, the certification of code and so on.
Just to show some examples: DimDim “We have synchronized this release to match the latest hosted version and released the complete source code tree. Bear in mind that features which require the Dimdim meeting portal (scheduling & recording to note) are not available in open source. There is also no limit to the number of attendees and meetings that can be supported using the Open Source Community Edition.” If you compare the editions, it is possible to see that the difference lies (apart from the scheduling and recording) in support and the availability of professional services (like custom integration with external authentication sources).
Alfresco: The difference in source code lies in the clustering and high-availability support and the JMX management extensions (all of which may be replicated with some effort by using pure OSS tools). Those differences are clearly relevant for the largest and most complex installations; from the point of view of services, the editions are differentiated through availability of support, certification (both of binary releases and of external stacks, like database and app server), bug fixing, documentation, availability of upgrades and training options.
Cynapse (an extremely interesting group collaboration system): The code difference lies in LDAP integration and clustering; the service difference lies in support, availability of certified binaries, knowledgebase access and official documentation.
OpenClinica (a platform for the creation of Electronic Data Capture systems used in pharmaceutical trials and in data acquisition in health care); from the web site: “OpenClinica Enterprise is fully supported version of the OpenClinica platform with a tailored set of Research Critical Services such as installation, training, validation, upgrades, help desk support, customization, systems integration, and more.”
During the compilation of the second FLOSSMETRICS database I found that the majority of “open core” models were actually moving from the original definition to an hybrid monetization model, that brings together several separate models (particularly the “platform provider”, “product specialist” and the proper “open core” one) to better address the needs of customers. The fact that the actual percentage of code that is not available under an OSS license is shrinking is in my view a positive fact: because it allows for the real OSS project to stand on its own (and eventually be reused by others) and because it shows that the proprietary code part is less and less important in an ecosystem where services are the real key to add value to a customer.
Conference announcement: SITIS09 track, Open Source Software Development and Solution
Posted by cdaffara in OSS adoption, OSS business models, blog on July 3rd, 2009
I am pleased to forward the conference announcement; I believe that my readers may be interested in the OSSDS track on open source development and solutions:
The 5th International Conference on Signal Image Technology
and Internet Based Systems (SITIS’09)
November 29 – December 3, 2009
Farah Kenzi Hotel
Marrakech, Morocco
http://www.u-bourgogne.fr/SITIS
In cooperation with ACM SigApp.fr, IFIP TC 2 WG 2.13, IEEE (pending)
The SITIS conference is dedicated to research on the technologies used to represent, share and process information in various forms, ranging multimedia data to traditional structured data and semi-structured data found in the web. SITIS spans two inter-related research domains that increasingly play a key role in connecting systems across network centric environments to allow distributed computing and information sharing.
SITIS 2009 aims to provide a forum for high quality presentations on research activities centered on the following tracks:
- The focus of the track “Information Management & Retrieval Technologies” (IMRT) is on the emerging modeling, representation and retrieval techniques
- that take into account the amount, type and diversity of information accessible in distributed computing environment. The topics include data semantics and ontologies, spatial information systems, Multimedia databases, Information retrieval and search engine, and applications.
- The track “Web-Based Information Technologies & Distributed Systems” (WITDS) is devoted to emerging and novel concepts, architectures and methodologies for creating an interconnected world in which information can be exchanged easily, tasks can be processed collaboratively, and communities of users with similarly interests can be formed while addressing security threats that are present more than ever before. The topics include information system interoperability, emergent semantics, agent-based systems, distributed and parallel information management, grid, P2P, web-centric systems, web security and integrity issues.
- The track “Open Source Software Development and Solution” (OSSDS) focuses on new software engineering method in distributed and large scaled environments, strategies for promoting, adopting, and using Open Source Solutions and case studies or success stories in specific domains. The topics include software engineering methods, users and communities’ interactions, software development platforms, open Source developments and project management, applications domain, case studies.
In addition to the above tracks, SITIS 2009 includes workshops; the final list of workshop will be provided later.
Submission and publication
————————–
The conference will include keynote addresses, tutorials, and regular and workshop sessions. SITIS 2009 invites submission of high quality and original papers on the topics of the major tracks described below. All submitted papers will be peer-reviewed by at least two reviewers for technical merit, originality, significance and relevance to track topics.
Papers must be up to 8 pages and follow IEEE double columns publication format. Accepted papers will be included in the conference proceedings and published by IEEE Computer Society and referenced in IEEE explore and major indexes.
Submission site : http://www.easychair.org/conferences/?conf=sitis09
Important dates
—————-
* Paper Submission: July 15th, 2009
* Acceptance/Reject notification: August 15th, 2009
* Camera ready / Author registration: September 1st, 2009
Local organizing committee (Cadi Ayyad University, Morocco)
————————————————————
* Aziz Elfaazzikii (Chair)
* El Hassan Abdelwahed
* Jahir Zahi
* Mohamed El Adnani
* Mohamed Sadgal
* Souad Chraibi
* Said El Bachari
Track Open Source Software Development and Solutions (OSSDS)
IFIP TC 2 WG 2.13
————————————————————-
The focus of this track is on new software engineering method for Free/Libre and Open Source Software (FLOSS) development in distributed and large scaled
environments, strategies for promoting, adopting, using FLOSS solutions and case studies or success stories in specific domains.
Software Engineering methods, users and communities interactions, software
development platforms:
* Architecture and patterns for FLOSS development
* Testing and reliability of FLOSS
* Software engineering methods in distributed collaborative environments
* Licencing and other legal issues
* Documentation of FLOSS projects
* CASE tool to support FLOSS development
* Agile principles and FLOSS development
* Mining in FLOSS projects
Applications domain, case studies, success stories:
* Geospatial software, services and applications
* Bioinformatics
* FLOSS for e-government and e-administration
* FLOSS in public sector (e.g. education, healthcare…)
* FLOSS solutions for data intensive applications
* FLOSS and SOA, middleware, applications servers
* FLOSS for critical applications
* FLOSS in Grid and P2P environments
* Tools and infrastructures for FLOSS development
* Scientific computing
* Simulation tools
* Security tools
Development and project management:
* Ecology of FLOSS development
* FLOSS stability, maintainability and scalability
* FLOSS evaluation, mining FLOSS data
* FLOSS and innovation
* Experiments, reports, field studies and empirical analysis
* FLOSS for teaching software engineering
* Revenue models
* Security concerns in using FLOSS
* Users involvement in design and development of FLOSS
* Building sustainable communities
Track Chairs
* Thierry Badard (University of Laval, Canada)
* Eric Leclercq (University of Bourgogne, France)
Program Committee
Abdallah Al Zain (Heriot-Watt University, UK)
Claudio Ardagna (Universita degli Studi di Milano, Italy)
Carlo Daffara (Conecta, Italy)
Ernesto Damiani (University of Milan, Italy)
Mehmet Gokturk (Gebze Institute of Technology, Turkey)
Scott A. Hissam (Carnegie Mellon University, USA)
Frédéric Hubert (University of Laval, Canada)
Puneet Kishor (University of Wisconsin-Madison and Open Source Geospatial
Foundation, USA)
Frank Van Der Linden (Philips, Netherlands)
Gregory Lopez (Thales group, France)
Sandro Morasca (Universita degli Studi dell’Insubria, Italy)
Pascal Molli (University of Nancy, France)
Eric Piel (University of Delft, The Netherlands)
Eric Ramat (University of Littoral, France)
Sylvain Rampacek (University of Bourgogne, France)
Marinette Savonnet (University of Bourgogne, France)
Charles Schweik, University of Massachussets, Amherst, USA)
Alberto Sillitti (University of Bolzano, Italy)
Megan Squire (Elon University, USA)
Marie-Noelle Terrasse (University of Bourgogne, France)
Christelle Vangenot (EPFL, Switzerland)
Just finished: the final edition of the SME guide to open source
Posted by cdaffara in OSS adoption, OSS business models, OSS data on July 2nd, 2009
It has been an absolutely enjoyable activity to work in the context of the FLOSSMETRICS project with the overall idea of helping SMEs to adopt, and migrate to, open source and free software. My proposed approach was to create an accessible and replicable guide, designed to help both those interested in exploring what open source is, and in helping companies in the process of offering services and products based on OSS; now, two years later, I found references to the previous editions of the guide in websites across the world, and was delighted in discovering that some OSS companies are using it as marketing material to help prospective customers.
So, after a few more months of work, I am really happy to present the fourth and final edition of the guide (PDF link) that will (I hope) improve in our previous efforts. For those that already viewed the previous editions, chapter 6 was entirely rewritten, along with a new chapter 7 and a newly introduced evaluation method. The catalogue has been expanded and corrected in several places (also thanks to the individual companies and groups responsible for the packages themselves) and the overall appearance of the PDF version should be much improved, compared to the automatically generated version.

I will continue to work on it even after the end of the project, and as before I welcome any contribution and suggestion.