Posts Tagged open source
And now, for something totally different: EveryDesk!
Posted by cdaffara in OSS adoption, blog on June 21st, 2010
Now that most of our work for FLOSSMETRICS is ended, I had the opportunity to try and work on something different. As you know, I worked on bringing OSS to companies and public administration for nearly 15 years now, and I had the opportunity to work in many different projects with many different and incredible people. One of the common things that I discovered is that to increase adoption it is necessary to give every user a distinct advantage in using OSS, and to make the exploratory process easy and hassle-free.
So, we collected most of the work done in past projects, and developed a custom desktop, designed to be explorable without installation, fast and designed for real world use; EveryDesk is a reinterpretation of the Linux desktop, designed to be used in public administrations or as an enterprise desktop. EveryDesk is a real OS on a USB key, not a live CD; this way the system allows for extensive customization and adaptation to each Public Administration need It is the result of the open sourcing of part of our HealthDesk system, designed using the result of our past European projects COSPA (a large migration experiment for European Public Administrations), SPIRIT (open source health care), OpenTTT (OSS technology transfer) and CALIBRE (open source for industrial environments).
EveryDesk is a binary image designed for 4GB USB keys, easy to install with a single command both on Linux and Windows, simple to replicate and adapt. It does provide a simple and pleasing user interface, with several pre-installed applications and native support for Active Directory. EveryDesk supports roaming/nomadic work through a special mode that stores all user data on a remote SMB server (both Samba and Windows are supported). This way, the user’s USB key contains no personal data, and can be used in environments that manage sensitive data, like health care or law enforcement.
The files and images can be downloaded from the SourceForge project page.

EveryDesk integrates a simple and easy to use menu, derived from Novell usability research studies, providing one-click access to individual programs, documents, places; easy installation of new software or updates, thanks to the fully functional package manager.


EveryDesk includes support for Terminal Services, VNC, VmWare View and other remote access protocols. One peculiarity we are quite happy with is the idea of simplified VDI; basically, EveryDesk integrates the open source edition of VirtualBox, and allows for mounting the disk images remotely – so the disk storage is remote, and the execution is local. This way, VDI can be implemented by adding only storage (that is cheap and easy to manage) and avoiding all the virtualization infrastructure.

The seamless virtualization mode of VirtualBox allows for a quite good integration between Windows (especially Windows 7) and the local environment. Coupled with the fact that the desktop is small and runs in less than 100MB (with both Firefox and OpenOffice.org, it takes only 150MB) it makes for a good substitute of a traditional thin client, is manageable through CIM, and is commercially supported. Among the extensions developed, we have a complete ITIL compliant management infrastructure, and digitally-signed log storage for health care and law enforcement applications.
For more information: our health care home page, main site, on twitter, facebook, and of course here!
About software forges
Posted by cdaffara in blog, divertissements on June 17th, 2010
I had the opportunity to talk a little bit with Dirk Riehle at LinuxTag about business models, collaboration and infrastructures, and one of the arguments was about software forges, like SourceForge or GForge. I would like to provide a little bit of overview of our discussion, along with my reasoning about the future of such forges.
First of all, I am a strong believer in the idea that forges were one of the important elements for the maturation and creation of a large scale market of users and developers of open source; forges provided free, simple and no-cost infrastructure for the basic necessities of a project, like file storage, CVS, mailing lists and so on. In this sense, forges also helped in discovering software, by providing basic taxonomies of software code, and comprehensive search facilities.
But two main aspects are in my opinion reducing the potential of forges for recent projects, namely distributed development and information dissemination. One of the important evolutions in code development has been the widespread adoption of distributed version control, through Git, Bazaar, Mercurial and (to a lesser extent) other minor solutions. Git, for example, substantially increased the productivity of projects like Wine, and provide a good management framework for large scale development by nearly independent group, like in the case of the Linux kernel.
The other aspect is related to information dissemination: what happens to a project is lost between bug tracking, mailing lists, forum (why the replication of features? how to find if something was already solved in some other place?); projects are difficult to interact one with the other, with the impossibility of tracking evolution of one project from another without passing from one person in the middle subscribed to both. And, as Dirk graciously conceded, managing or adapting a forge is a real nightmare ![]() I remember our past work in the Spirit forge (a healthcare-oriented forge, that used digital certificates to authenticate and sign code entered in the platform) and still got the shivers.
I remember our past work in the Spirit forge (a healthcare-oriented forge, that used digital certificates to authenticate and sign code entered in the platform) and still got the shivers.
For this reason, I believe that future forges will be structurally different from the current ones: they will be based on small, efficient pieces, for example a central Git repo, that is enhanced by external modules that subscribe to modifications in the code stream and provide this information to higher-level applications, that for example produce graphs or link each atomic action to a wiki or tracking system. By moving things from a monolithic tool to loosely coupled pieces, we can end up with something that is more “facebook-like” than forge like, with individual apps that provide for example code quality services (like Sonar) or visualization services. I am a strong believer in a publish-subscribe mechanism for this, for example through XMPP, because it allows to solve easily the problem of how to track strongly coupled projects. For example, if my code is dependent on an external project I can subscribe to its own code announcement strams, or issue streams, since the same issues will probably apply to my code as well; this without an explicit interaction, and with the opportunity to link issues to individual actions (commits, reports, etc.) that remain valid even if I fork the library, or act independently on modifications that will eventually be merged in a single tree. I believe that in the future the number of strong or weak coupling will increase, and this will seriously limit the capabilities of current forges.
Why HTML5&Co are better for browsers, and what is still missing
Posted by cdaffara in divertissements on May 27th, 2010
It seems that WebM captured the interest of many that were looking for a potential escape from the HTML5 video deadlock (h264 or theora); Google managed to create a potentially suitable alternative, that seems to be relatively risk-free in terms of patents, while providing reasonable overall quality (especially for the HD video range; at lower bitrate and resolution still needs substantial work). This reignited the flash/html5 war, spurred by Apple and its ban of everything Flash or Flash-like. I have read lots of comments ranging from the “flash will be with us forever” to “flash is already dead”. The dichotomy presented is false, for several reasons; I will try to highlight a few of the comments I received, along with my thoughts:
Flash player is on 98% of the internet-connected devices. While this may be true (I doubt it, as most smartphones are actually internet-connected, and Flash does not work there, or is such a sad joke that it should be left for when the kids are asleep), it does not work on the majority of new internet devices, that are either pads, ARM-based devices or systems where Flash has not a good enough performance. Google recently mentioned that they activate 100000 Android devices per day, Apple is more or less in the same range, and there is still no Flash there (t will be – but I still suspect that the experience will not be that good to make it usable). The Flash player is still slow and complex, and unless the technology changes radically, I suspect that it will be still quite slow (unless for single-window, tailored small games as Kongregate demonstrated recently).
Video is the only important thing. Actually, video is important, but Flash is much more than video. While HTML5 allows for some simple games to be created entirely in the browser, going much farther than PacMan is still difficult.HTML%, Canvas, WebGL, Javascript and much more need to go beyond what they provide today; the road seem to go there, but is not there yet.
Video is important, and H264 is the best thing that we have. H264 is a very good standard, and properly implemented (as an example, within the x264 encoder) is really among the state of the art. But – a small and unscientific comparison I performed yesterday seem to indicate that actually WebM is fast and simple, as previous claim by On2 indicated. The simplicity of the transforms and the linear structure should lend well to an embedded implementation, that is actually just a specialized coding on a collection of onboard DSPs.
Flash works well enough right now. Actually, no. The player duplicates most of what is already present within a modern browser: it comes with its own language (quite similar to JavaScript, actually), its own Just-in-Time compiler, its own widgets and interaction tools, its own video and canvas implementation, and moving/activating objects between the Flash boundary and the browser is akin to pull concrete blocks through a straw. Not only the replication of functionality prevents any optimization, but the presence of what is essentially an alien object with its own activity loop creates an endless string of difficulties whenever you need to integrate non-trivial multimedia content with non-flash objects. In fact, one of the reason for pushing open video within HTML5 is to have a much better user experience with lower CPU and resource usage; and as soon as YouTube forces people to use a WebM enabled browser to experience it better, you will see a much quicker adoption.
Most of the missing things are already being worked on, both in the JavaScript engines, within subprojects like Websockets, packages (be it Google-style packages for the web store, or Jar-like packages), video, audio and much more. There is one thing that is missing, and that will be probably be introduced soon: DRM. I know – DRM is a useless gimmick, that up to now has not demonstrated any capability to hinder unlicensed copying, and on the contrary seem to be quite effective at pissing people off.
The reality is that most content providers are requiring a form of DRM – be it effective or not – because this way they have a legal way to ask damages, using the DMCA or similar legislation that were introduced around the world. Yes, most current DRM schemes are not designed to be effective, but to provide a legal instrument. That’s why some video vendors insist that HTML5 is not suited for video distribution: because it does not have a protection form, that (even if easily avoidable) provides a tool to ask for damages and external authority control. I am quite confident that sooner or later, someone will introduce a DRM option to provide optional content protection; at that point, Flash or Silverlight will provide no substantial technical or business advantage, and will be on the contrary disadvantages, especially in up-and-coming platforms.
An analysis of WebM and its patent risk – updated
Posted by cdaffara in divertissements on May 25th, 2010
[I have updated the post below, with some considerations from the past similar initiative by Sun (now Oracle) of the Open Media Commons, that designed a codec based on enhancement of H261+]
There is a substantial interest on the recently released WebM codec and specification from Google, the result of open sourcing the VP8 SDK from the recently acquired company On2. It clearly sparked the interest of many the idea of having a reasonably good, open and freely redistributable codec for which the patents are freely licensed in a way that is compatible with open source and free software licensing; at the same time, the results of initial analysis by Dark Shikari (real name Jason Garrett-Glaser, the author of the extraordinary x264 encoder) and others seem to indicate that the patent problem is actually not solved at all.
I believe that some of the comments (especially in Dark Shikari’s post) are a little bit off mark, and should be taken in the correct context; for this reason, I will first of all provide a little background.
What is WebM? WebM is the result of the open sourcing of the VP8 encoding system, previously owned by On2 technologies. It is composed of three parts: the bitstream specification, the reference encoder (that takes an uncompressed video sequence and creates a compressed bitstream) and the reference decoder (that takes the compressed bitstream and generates a decoded video stream). I stress the word “reference” because this is only one of the possible implementations; exactly like the H264 standard, there are many encoders and decoders, optimized for different things (or of different quality). An example of a “perfect” encoder may be a program that generates all possible bit sequences, decodes them (discarding the non-conforming ones), compares with the uncompressed original video and retains the one with the highest quality (measured using PSNR or some other metric). It would make for a very slow encoder, but would find the perfect sequence; that is, the smallest one that has the highest PSNR; on the other hand, decoders differ in precision, speed and memory consumption, making it difficult to decide which is the “best”.
Before delving into the specific of the post, let’s mention two other little things: to the contrary of what is widely reported, Microsoft VC1 never was “patent free”. It was free for use with Windows, because Microsoft was assumed to have all the patents necessary for its implementation; but as VC1 was basically an MPEG4 derivative, most of the patents there applies to VC1 as well, plus some other that were found later for the enhanced filtering that is part of the specification (and that were also part of the MPEG4 Advanced profile and H264). It was never “patent free”, it was licensed without a fee. (that is a substantially different thing – and one of the reasons for its disappearance. MS pays the MPEG-LA for every use of it, and receives nothing back, making it a money-loss proposition…)
Another important aspect is the prior patent search: it is clear (and will be evident a few lines down) that On2 made a patent search to avoid specific implementation details; the point is that noone will be able to see this pre-screening,to avoid additional damages. In fact, one of the most brain damaged things of the current software patent situation is the fact that if a company performs a patent search and finds a potential infringing patent it may incur in additional damages for willful infringement (called “treble damages”). So, the actual approach is to perform the same analysis, try to work around any potential infringing patent, and for those “close enough” cases that cannot be avoided try to steer away as much as possible. So, calling Google out for releasing the study on possible patent infringement is something that has no sense at all: they will never release it to the public.
So, go on with the analysis.
Dark Shikari makes several considerations, some related to the implementation itself, and many related to its “patent status”. For example: “VP8’s intra prediction is basically ripped off wholesale from H.264″, without mentioning that the intra prediction mode is actually pre-dating H264; actually, it was part of Nokia MVC proposal and H263++ extensions published in 2000, and the specific WebM implementation is different from the one mentioned in the “essential patents” of H264 as specified by the MPEG-LA.
If you go through the post, you will find lots of curious mentions of “sub-optimal” choices:
- “i8×8, from H.264 High Profile, is not present”
- “planar prediction mode has been replaced with TM_PRED”
- “VP8 supports a total of 3 reference frames: the previous frame, the “alt ref” frame, and the golden frame”
- “VP8 reference frames: up to 3; H.264 reference frames: up to 16″
- “VP8 partition types: 16×16, 16×8, 8×16, 8×8, 4×4; H.264 partition types: 16×16, 16×8, 8×16, flexible subpartitions (each 8×8 can be 8×8, 8×4, 4×8, or 4×4)”
- “VP8 chroma MV derivation: each 4×4 chroma block uses the average of colocated luma MVs; H.264 chroma MV derivation: chroma uses luma MVs directly”
- “VP8 interpolation filter: qpel, 6-tap luma, mixed 4/6-tap chroma; H.264 interpolation filter: qpel, 6-tap luma (staged filter), bilinear chroma”
- “H.264 has but VP8 doesn’t: B-frames, weighted prediction”
- “H.264 has a significantly better and more flexible referencing structure”
- “having as high as 6 taps on chroma [for VP8] is, IMO, completely unnecessary and wasteful [personal note: because smaller taps are all patented
 ]“
]“ - “the 8×8 transform is omitted entirely”
- “H.264 uses an extremely simplified “DCT” which is so un-DCT-like that it often referred to as the HCT (H.264 Cosine Transform) instead. This simplified transform results in roughly 1% worse compression, but greatly simplifies the transform itself, which can be implemented entirely with adds, subtracts, and right shifts by 1. VC-1 uses a more accurate version that relies on a few small multiplies (numbers like 17, 22, 10, etc). VP8 uses an extremely, needlessly accurate version that uses very large multiplies (20091 and 35468)”
- “The third difference is that the Hadamard hierarchical transform is applied for some inter blocks, not merely i16×16″
- “unlike H.264, the hierarchical transform is luma-only and not applied to chroma “
- “For quantization, the core process is basically the same among all MPEG-like video formats, and VP8 is no exception (personal note: quantization methods are mostrly from MPEG1&2, where most patents are already expired – see the list of expired ones in MPEG-LA list)”
- “[VP8 uses] … a scheme much less flexible than H.264’s custom quantization matrices, it allows for adjusting the quantizer of luma DC, luma AC, chroma DC, and so forth, separately”
- “The killer mistake that VP8 has made here is not making macroblock-level quantization a core feature of VP8. Algorithms that take advantage of macroblock-level quantization are known as “adaptive quantization” and are absolutely critical to competitive visual quality” (personal note: it is basically impossible to implement adaptive quantization without infringing, especially for patents issued after 2000)
- “even the relatively suboptimal MPEG-style delta quantizer system would be a better option. Furthermore, only 4 segment maps are allowed, for a maximum of 4 quantizers per frame (both are patented: delta quantization is part of MPEG4, and unlimited segment maps are covered)”
- “VP8 uses an arithmetic coder somewhat similar to H.264’s, but with a few critical differences. First, it omits the range/probability table in favor of a multiplication. Second, it is entirely non-adaptive: unlike H.264’s, which adapts after every bit decoded, probability values are constant over the course of the frame” (probability tables are patented in all video coding implementations, not only MPEG-specific ones, as adapting probability tables)
- “VP8 is a bit odd… it chooses an arithmetic coding context based on the neighboring MVs, then decides which of the predicted motion vectors to use, or whether to code a delta instead” (because straight delta coding is part of MPEG4)
- “The compression of the resulting delta is similar to H.264, except for the coding of very large deltas, which is slightly better (similar to FFV1’s Golomb-like arithmetic codes”
- “Intra prediction mode coding is done using arithmetic coding contexts based on the modes of the neighboring blocks. This is probably a good bit better than the hackneyed method that H.264 uses, which always struck me as being poorly designed”
- residual coding is different from both CABAC and CAVLC
- “VP8’s loop filter is vaguely similar to H.264’s, but with a few differences. First, it has two modes (which can be chosen by the encoder): a fast mode and a normal mode. The fast mode is somewhat simpler than H.264’s, while the normal mode is somewhat more complex. Secondly, when filtering between macroblocks, VP8’s filter has wider range than the in-macroblock filter — H.264 did this, but only for intra edges”
- “VP8’s filter omits most of the adaptive strength mechanics inherent in H.264’s filter. Its only adaptation is that it skips filtering on p16×16 blocks with no coefficients”
What we can obtain from this (very thorough – thanks, Jason!) analysis is the fact that from my point of view it is clear that On2 was actually aware of patents, and tried very hard to avoid them. It is also clear that this is in no way an assurance that there are no situation of patent infringements, only that it seems that due diligence was performed. Also, WebM is not comparable to H264 in terms of technical sophistication (it is more in line with MPEG4/VC1) but this is clearly done to avoid recent patents; some of the patents on older specification are already expired (for example, all France Telecom patents on H264 are expired), and in this sense Dark Shiraki claims that the specification is not as good as H264 is perfectly correct. It is also true that x264 beats the hell on current VP8 encoders (and basically every other encoder in the market); despite this, in a previous assessment Dark Shiraki performed a comparison of anime (cartoon) encoding and found that VP7 was better than Apple’s own H264 encode – not really that bad.
{kind=link}
The point is that reference encoders are designed to be a building block, and improvement (in respect of possible patents in the area) are certainly possible; maybe not reaching the level of x264 top quality (I suspect the psychovisual adaptive schema that allowed such a big gain in x264 are patented and non-reproducible) but it should be a worthy competitor. All in all, I suspect that MPEGLA rattling will remain only noise for a long, long time.
Update: many people mentioned in blog posts and comments that Sun Microsystem (now Oracle) in the past tried a very similar effort, namely to re-start development of a video codec based on past and expired patents, and start from there avoiding active patents to improve its competitiveness. They used the Open Media Commons IPR methodology to avoid patents and to assess patent troubles, and in particular they developed an handy chart that provides a timeline of patents and their actual status (image based on original chart obtained here):
{kind=link}
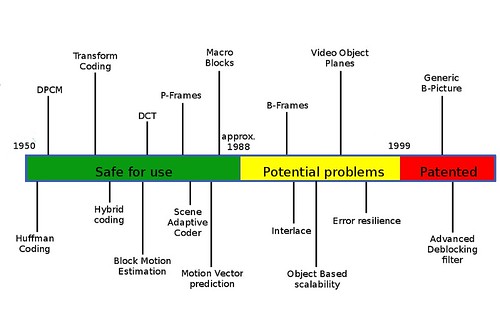
As it can be observed, most of the techniques encountered in the OMV analysis are still valid for VP8 (the advanced deblocking filter of course is present in VP8, but with a different implementation). It also provides additional support to the idea that On2 developers were aware of patents in the area, and came out with novel ideas to work around existing patents, much like Sun with its OMV initiative. In the same post, the OMV block structure graph includes several “Sun IPR” parts, that are included in the OMV specification (the latest version available here (pdf) – the site is not updated anymore) and that maybe may be re-used, with Oracle explicit permission, in WebM. And to answer people asking for “indemnification” from Google, I would like to point my readers to a presentation of OMV and in particular to slide 10: “While we are encouraged by our findings so far, the investigation continues and Sun and OMC cannot make any representations regarding encumbrances or the validity or invalidity of any patent claims or other intellectual property rights claims a third party may assert in connection with any OMC project or work product.” This should put to rest the idea that Sun was indemnifying people using OMV, exactly like I am not expecting such indemnification from Google (or any other industry player, by the way).
How to analyse an OSS business model – part five
Posted by cdaffara in OSS business models on May 19th, 2010
(part five of an ongoing series. Previous parts: part one, two, three, four).
Marten Mickos (of MySQL fame) once said that “people spend time to save money, some spend money to save time“. This consideration is at the basis of one of the most important parameter for most OSS companies that use the open core or freemium model, that is the conversion rate (the percentage of people that pays for enterprise or additional functionalities, versus the total amount of users). With most OSS companies reaching less than 0.1%, and only very few capable of reaching 1%, one of the obvious goals of CEOs of said open source companies is to find a way to “convert” more users to paying for services, or to increase the monetization rate.
My goal today is to show that such effort can have only a very limited success, and may be even dangerous for the overall acceptance of the software project itself.
Let’s start with an obvious concept: everyone has a resource at his/her disposal, namely time. This resource does have some interesting properties:
- it is universal (everyone has time)
- it is inflexible (there are 24 hours in a day, and anything you can do will not change it)
- efficiency (work done in the unit of time) does have a lower bound of zero, and an higher bound that depends on many factors; efficiency can vary by one order of magnitude or more.
Another important parameter is the price per hour for having something done. At this point, there is a common mistake, that is assuming that there is a fixed hourly rate, or at least a lower bound on hourly rate. This is clearly wrong, because the price per hour is the simple ratio between what someone is paying you to do the work and the amount of time required for that action; so if no-one pays you, that ratio is zero. So, let’s imagine someone working for a web company, and one of the activities requires a database. Our intrepid administrator will start learning something about MySQL, will work diligently and install it (ok, nowadays it’s nearly point-and-click. Imagine it done a few years ago, with compiles and all that stuff).
This system administrator will never pay for MySQL enterprise, or whatever, because its pay is fixed, and there is no allocated budget for him to divert money to external entities. So, whatever is done by MySQL to monetize the enterprise version, there will be simply no way to obtain money from the people that is investing time, unless you sabotage the open source edition so that you are forced to pay for the enterprise one. But what will happen then? People will be forced to look at alternatives, because in any case time is the only resource available to them.
This basic concept is valid even when companies do have budget available. Consider the fact that the average percentage of revenues invested in ICT (information and communication technology) by companies is on average around 5%, with some sectors investing slightly less (4%) up to high-tech companies investing up to 7%. This percentage is nearly fixed, valid for small to large companies and across countries and sectors; this means that the commercial OSS company is competing for small slices of budget, and its capability to win is related mainly to the perceived advantages of going “enterprise” versus investing personnel time.
Does it means that trying to increase conversion rate is useless? Not exactly. The point is that you cannot address those users that have no budget available, as those will never be able to pay for your enhanced offering; you have two different possible channels: those that are using your product and may have the potential to pay, or address the group of non-users with the same demographics. So, the reality is that mining current users is potentially counterproductive, and it is more sensible to focus on two interlocking efforts:
- increase the number of adopters, and
- make sure that people knows about the commercial offering.
This can be performed “virally”, that is by creating an incentive for people to share the knowledge of your project with others, which is very fast, efficient and low-cost; however, this approach does have the disadvantage that sharing will happen within a single group of peers. In fact, viral sharing happens within only homologous group, and this means that it is less effective for reaching those users that are outside the same group – for example, the non-users that we are pointing at. This means that purely viral efforts are not capable of reaching your target – you need to complement it with more traditional marketing efforts.
Next: resource and development sharing, or how to choose your license depending on your expectations of external participation.
On open source competence centers
Posted by cdaffara in OSS adoption on April 26th, 2010
Just a few days ago, Glynn Moody posted a tweet with the message: “Italy to begin an open source competence centre”; a result of the recent EU project Qualipso, created with the purpose to identify barriers to OSS adoption, quality metrics and with the explicit target of creating a network of OSS competence centers, sharing the results of the research effort and disseminating it with the European community of companies and public administration. For this reason, the project created more than one competence center, and created a network (that you can find under this website) to cover not only Europe, but China, India and Japan as well. This is absolutely a great effort, and I am grateful to the Commission and the project participants for their work (hey, they even cited my work on business models!)
There is, however, an underlying attitude that I found puzzling – and partially troubling as well. The announcement mentioned the competence center of Italy, and was worded as there was no previous such effort in that country. If you go to the network website, you will find no mention of any other competence center there, even when you consider that the Commission already has a list of such centers (not much updated, though) and that on OSOR there is even an official group devoted to Italian OSS competence centers, among them two in Friuli (disclaimer: I am part of the technical board of CROSS, and work in the other), Tuscany, Trentino, Umbria, Emilia (as part of the PITER project), a national one and many others that I probably forgot. Then we have Austria, Belgium, Denmark, Estonia, Finland, Germany, Ireland, Malta, Netherlands, Nordic Countries and many others. What is incredible is that most of these centers… actually don’t link one with the other, and they hardly share information. The new Qualipso network of competence centers does not list any previous center, nor does it point to already prepared documentation – even by the Commission. The competence center network website does not link to OSOR as well, nor does it links to other projects – past or current.
I still believe that competence centers are important, and that they must focus on what can be done to simplify adoption – or to turn adoption into a commercially sustainable ecosystem, for example by facilitating the embracing of OSS packages by local software companies. In the past I tried to summarize this in the following set of potential activities:
- Creating software catalogs, using an integrated evaluation model (QSOS, Qualipso, FLOSSMETRICS-anything, as long as it is consistent)
- For selected projects, finds local support companies with competence in the identified solution
- Collect the needs of potential OSS users, using standardized forms (Technology Request/Technology Offer, TR/TO) to identify IT needs. Find the set of OSS projects that together satisfies the Technology Request; if there are still unsatisfied requirements, join together several interested users to ask (with a commercial offer) for a custom-made OSS extension or project
- Aggregate and restructure the information created by other actors, like IST, IDABC, individual national initiatives (OSOSS, KBST, COSS, …)
This models helps in overcoming several hurdles to OSS adoption:
- Correctly identify needs, and through analysis of already published TR can help in aggregating demand
- Helps in finding appropriate OSS solutions, even when solutions are created through combination of individual pieces
- Helps in finding actors that can provide commercial support or know-how
It does have several potential advantages over traditional mediation services:
- The center does NOT participate in the commercial exchange, and in this sense acts as a pure catalyst. This way it does not compete with existing OSS companies, but provides increased visibility and an additional dissemination channel
- It remains a simple and lean structure, reducing the management costs
- By reusing competences and information from many sources, it can become a significant learning center even for OSS companies (for example, in the field of business models for a specific OSS project)
- It is compatible with traditional IT incubators, and can reuse most of the same structures
Most of this idea revolves around the concept of sharing effort, and reusing knowledge already developed in other areas or countries. I find it strange that the most difficult idea among these competence centers is… sharing.
(update: corrected the network project name – Qualipso, not Qualoss. Thanks to Matteo for spotting it.)
How to analyse an OSS business model – part four
Posted by cdaffara in OSS business models on April 12th, 2010
Welcome to the fourth part of our little analysis of OSS business models (first part here, second part here, third part here). It is heavily based on the Osterwalder model, and follows through the examination of our hypothetical business model; after all the theoretical parts, we will try to add a simple set of hands-on exercises and tutorials based on a more or less real case. We will focus today on the remaining parts of our model canvas (with less detail, as those parts are more or less covered by every business management course…), and will start a little bit of “practical” exploration, to create the actors/actions model that was discussed in the previous instalments.
Cost structure: this is quite simple – the costs incurred during the operation of our business model. There are usually two kind of models, called “cost-driven” (where the approach is minimization of costs) or “value-driven” (where the approach is the maximization of value creation). Most models are a combination of the two; for example, many companies have a low-cost offering to increase market share, and a value offering with an higher cost and higher overall quality. In open source companies it is usually incorrect to classify the open source edition as “cost-driven”, unless a specific price and feature difference is applied between a low-level and high-level edition.
Key partners: do our company partners with external entities? Common examples are resellers, external support providers, and so on. Additional examples may be partnerships with other companies or external groups for co-development of the OSS components (even competitors may share work on improving a reciprocally useful OSS package); sometimes the partnership may be informal (for example, with an OSS community) but fundamental as well.
Key activities: what is the basis of our work in our hypothetical OSS company? Of course, software development may be a big part; other examples are marketing, support… every company do have a specific mix, that is easily recognized simply by looking at what each person inside the company is doing right now.
Channels: how do we contact our customers, or potential ones? Directly? Through an external channel? Each channel provide different properties; web marketing is different from web word-of-mouth, exactly like radio advertising is different from print advertising. Choosing an appropriate channel is adifficult art, and is something that changes with time.
Customer relationships: How does the customer (or potential customer) interact with our company? Only through the software? Through online or in-person channels, like workshops? Support is self-service (the customer does it by itself) or requires human interaction? Is this interaction monitored? By who? A special case is handling the relationship with contributors (that are offering something of value to the company, without an economic intermediation) and OSS communities, that should be handled as a distinct entity (and not simply a collection of individuals). In this area I depart a little bit from the original Osterwalder model, by including not only customers but any interacting actor that provides value to the company, in one form or the other; this allows us to model in a more accurate way all those interactions that are not strictly monetary,
Revenue streams: this is easy! How the money enters your company? Is it structured in one-time payments, multiple recurring payments? Are there alternative form of revenue?
Are you still with me? Now that you have collected all the data on your company, the fun begins. We need to draft the network of actors (like your key resources, customer segments, external contributors…) and link these actors together with their relationship and effect. Some relations may impact on specific variables while changing others (lowering the attractiveness of the community edition may increase conversion rates, but lower overall adoption rates).
In the next instalment we will provide an initial draft, and will later show how to convert this graph into a small and simple simulation.
A small and unscientific exploration of OSS license use
Posted by cdaffara in OSS data, divertissements on March 17th, 2010
I was intrigued by an excellent (as usual) post by Matthew Aslett of 451 group, titled “On the fall and rise of the GNU GPL“, where Matthew muses on the impact of cloud computing and other factors in the decreasing role of the GPLv2 versus other type of licenses. Simon Phipps twitted “you only consider number of projects and not volume of deployed code. I have never found number of projects compelling” which is something that I absolutely believe is true: it is, however, quite difficult to imagine other possible ways to measure “impact” of a project. Do we have to add a weight related to usage? Then, given the large use of Linux, GNOME or KDE, OpenOffice, Firefox we would probably see a huge jump in the GPL and MPL percentages, at the cost of added uncertainty (as usage estimates are variable at best). As I am desperately try to avoid doing real work, I started using the Ohloh web site to extract slightly less than 100 projects (among the “active” ones, so there is already an initial preselection), along with the licensing and the number of committers for each project. My idea was to measure not only the number of projects, but how many people contributes to each, to see if this scenario gives different percentages. In a sense, the number of committers is a measure of “activity” or community interest in a project, and so my idea was to see if there was a difference between the percentages obtained with only the amount of projects listed under a license, and the number of committers using a license. The result is this:
| license | projects | committers | %projects | %committers | blackduck % |
| gpl2 | 49 | 15878 | 52.1% | 62.9% | 48.83 |
| lgpl | 8 | 2286 | 8.5% | 9.1% | 9.35 |
| mit | 6 | 1668 | 6.4% | 6.6% | 4 |
| bsd | 8 | 1150 | 8.5% | 4.6% | 6.26 |
| gpl3 | 3 | 988 | 3.2% | 3.9% | 5.5 |
| php | 2 | 730 | 2.1% | 2.9% | 0.24 |
| cddl | 1 | 673 | 1.1% | 2.7% | 0.32 |
| mpl | 2 | 655 | 2.1% | 2.6% | 1.22 |
| apache | 10 | 557 | 10.6% | 2.2% | 4.02 |
| boost | 1 | 266 | 1.1% | 1.1% | |
| epl | 2 | 241 | 2.1% | 1.0% | 0.46 |
| python | 1 | 133 | 1.1% | 0.5% | |
| cpl | 1 | 6 | 1.1% | 0.0% | 0.56 |
The result is interesting: first of all, by looking in terms of contributors, the GPLv2 has an higher percentage of committers than that of projects; that is, there are more committers per project under the GPLv2 in respect to the normal share. The percentage of projects obtained is similar to that from BlackDuck (52.1% versus 48.83%), so I think that there is not too much bias in the choice of projects. The LGPL has more or less its fair share of committers, on a par with the number of projects and the results from BlackDuck. MIT is slightly higher, both in projects and commits, while the GPLv3 is under-represented – probably because the sample is too small, and in the project selection the “new” projects under the GPLv3 simply were not among the first 100 or so selected. A substantial difference exist for Apache-licensed projects, where the average number of committers seems smaller than its fair share; this may be an artefact of the project selected, or may be simply an effect of how Ohloh measures the active committers (I find strange that Boost has half of all the committers of all the Apache projects together!)
As I said, this is a little, unscientific experiment designed to explore what we can invent to better measure the “impact” of an OSS project. I would love to receive you comments and suggestions; on my side, I will try to leverage the FLOSSMETRICS database to try to find some numbers on a more consistent data sample.
How to analyse an OSS business model – part three
Posted by cdaffara in OSS business models on March 1st, 2010
Welcome to the third part of our little analysis of OSS business models (first part here, second part here). It is heavily based on the Osterwalder model, and follows through the examination of our hypothetical business model reaching the “key resources” part. After all the theoretical parts, we will try to add a simple set of hands-on exercises and tutorials based on a more or less real case.
The argument of this part is “resources”. Key resources are the set of assets (material and immaterial) that are the basis of the company operations. There may be physical resources (a production plant for example), intellectual resources (previously developed source code), human resources (your developers), financial resources (capital in the bank, loans) and other immaterial assets (your company name as a recognizable mark, “good standing” in terms of how your customer see your products…)
In our OSS company example, at least part of the immaterial assets are shared and publicly available, that is they are non rival. In our model we have a company that provides under an open source license the community edition of the software, while provides an “enterprise edition” with additional stability tests, support and so on. It is not correct to say that just because the source code is publicly available it is not monetizable; on the contrary, especially when the code is wholly owned in terms of copyright assignments it is potentially a valuable asset (for some examples, look at JBoss or MySQL). Even when the code is cooperatively owned (as in a pure GPLv2 with multiple contributors, like Linux) the “default place” is valuable in itself, and it is the reason why so many companies try to make sure that their code is included in the main kernel line, thus reducing future integration efforts and sharing the maintenance activities. Other examples that are relevant for the OSS case are trademarks (that are sometimes vigorously defended), “brand name”, the external ecosystem of knowledge; for example, all the people that is capable of using and managing a complex OSS offering, creating a networked value that grows with the number of participants in the net. People becoming RedHat certified, for example, increases the value of the RedHat ecosystem other than their own.
One of the most important resource is human: the people working on your code, installing it, supporting it. Most of those people in the OSS environment are not part of your company, but are an extremely important asset on their own thanks to their capability of contributing back time and effort. In exchange, these resources need to be managed, and that’s why you need sometimes figures like “community managers” (an excellent example is my friend Stefano Maffulli, community manager extraordinaire at Funambol) because exactly as you have a financial officer to check your finance (another essential resource) you should have a community manager for… the community.
To properly analyse your key resources, we can extend the network model created for the channel analysis (the actor/action model) and extend it a little bit, including the missing pieces. For example, we mentioned that a potential customer may be interested in our product. Who makes it? Of course, as any good OSS company, you have some pieces coming from the outside (other OSS projects), part coded by your developers and part coming as contribution from external groups. All of them are resources: the other OSS projects are key resources themselves, simply obtained without immediate cost but managed by some developers that are themselves a key resources; your internally developed source code is another key resource, and if you have large scale contributions from the outside those should be considered resources too, maybe not “key” resources but important nevertheless.
The main concept is: a resource is “key” if without it your company would not be able to operate; and whenever you have a key resource you should have a person that manages it with a clearly defined process.
Next: cost structure!
How to analyse an OSS business model – part two
Posted by cdaffara in OSS business models on February 18th, 2010
(now available: part three)
Welcome to the second part of our little analysis of OSS business models (first part here). It is based on the practical workshops that we do for companies, and so it does have a little “practical” feel to it; as for its theoretical background, it is heavily based on the Osterwalder model, that I found to be clear and comprehensible. It could be adapted easily to other conceptualizations and ontologies on how to describe a business model, if someone wants to use it in a teaching context.
In the first part of our analysis we discussed the basic background concepts and discussed the first two aspects: customer segments and value proposition. As I mentioned before, the analysis is iterative, and should be done collaboratively (for example, by all the people working in a specific group, or by all the managers). As an example of why it should be iterative, we discussed the value proposition: by identifying several different value propositions, we inherently created different customer segments, that receive different value from our hypothetical “widgets, inc.” and this fact can be leveraged by differentiated pricing or different adoption percentages (if the user perceives an higher value, the potential monetary payment may be higher or it may be encouraged in adoption). Let’s continue with channels!
Channels: under this name we can place all the different ways our company interacts with the outside world. A common mistake is to consider only “paid” transactions, while (especially for open source software) a substantial part of value comes from non-monetary interactions. Examples of channel purposes may be sales, distribution (both physical and intangible), company communication, brand channelling and so on. Most channels do have a simple definition (“sales”) while some are indirect and outside the control of the company, for example word of mouth. As any iPhone user can testimony, word of mouth is one of the most powerful information dissemination vehicle, because it is based upon trust in people you already know, and knows what you may be interested in; the flash mob success of some online games on Facebook is a slightly modified version of this principle.
In channel analysis, the various actors in a company try to imagine (or list) all the possible ways someone from the outside may interact with the company or its products. How can a potential customer discover about widgets, inc. products? What actions need to be performed to be able to evaluate or buy? To help in this mapping exercise you can perform what is called the actor/actions mapping. In this activity you start by listing all the actors that may be potentially interacting with you, your users (potential or not), people that may talk about your product… Everything. You start with a simple table, listing the actors and the possible actions that they may want to perform. As an example:
- unaware user: casually finds out about widgets, inc. through advertising, word of mouth, email campaign…
- potential user: wants more information. Can go to the web site, download from a mirror site, ask friends, look for reviews of the product….
- user: wants support. Contact through email, phone, web-based system, (if there is a physical part) may ask for replacement of something…
- user: wants a different contract. As before, can use email, phone, a CRM system…
- journalist: may ask for information to write a review…
The idea is to try to map all the roles, all the actions, and list all of them along with a sort of small description. Then, imagine yourself while performing the action listed within: who do you interact with? What are the precondition for performing such action? As for the customer segmentation, you repeat this exercise until nothing changes, and at this point you have a nice, complete map of all the in/out relationships of widgets, inc. with the outside world. At that point, you add a value to each channel, in terms of what does it costs to maintain it and what potential advantage brings to you. It is important to bring to the table all potential value (even negative value, or intangible) because for open source software a large part of the channel network will not be directly managed by widgets, inc. but will be handled by third parties that cannot be directly influenced. So, a very simple example: Acme corp. takes the community edition of our software, adds some bells and whistles and creates a nice service business based on that. Is it a value or not? It does have a positive value: enlarges the use base, may provide additional contributions; on the other hand, it competes directly in at least part of the user base. The decision on how to act (the strategy part) depends on what we want to optimize, and is something that is inherently dynamic; so as an example what is good in the beginning (when dissemination of information and adoption is more important than monetization) may not be optimal in a later stage.
This is one of the explanation for the change in licensing by OSS companies, after an initial stage designed to maximize recognition and community contributions; among the examples Wavemaker. As I wrote many times in the past, there is no “bad” or “good” license, the point is that the license should be adopted with a rationale; changing license (when possible) may increase certain factors and modify in general this global channel map for example by changing the percentage of developers that are adopting our software, thanks to a more permissive license. The various parameters of our model (percentage of enterprise/community, independent adopters that integrate our software within their products, return contributions…) are all dependent on many different external conditions that are a-priori imposed by how we manage the company. So, after the creation of our channel map, an important exercise is to try to estimate these parameters, or measure them if possible; this way, we can turn our model into a simulation, giving us insight and allowing us to experiment freely to find the best match for our needs. We will give an example of such parameters after all the pieces of our business model canvas are completed.
Next time: key resources!